Architectural Patterns for Microservices With Kubernetes
In this article, learn how deploying microservices using Kubernetes enhances and enforces key principles and patterns while offering additional benefits.
For some time, microservices have drawn interest across the architecture and software engineering landscape, and now, applications comprised of microservices have become commonplace. So what exactly is the definition of a microservice? That is somewhat of a loaded question as there is plenty of debate on granularity, segmentation, and what designates a microservice. For the purposes of this discussion, a microservices-based architecture is segmenting an application's units of work into discrete, interoperable components. This is a broad definition, but it is workable in that it identifies two foundational microservice concepts: discrete and interoperable.
Along with the technical and business benefits, a microservices-based application architecture brings its own set of challenges. These challenges have been met with solutions ranging from new architectural patterns to the evolution of tech stacks themselves. Kubernetes has become one of the technologies in the tech stack evolution. Deploying microservices using Kubernetes enhances and enforces key principles and patterns while offering additional benefits.
It's an Evolution, Not a Revolution
As with any technical evolution, taking the next step improves upon what has already been shown to be successful while removing barriers to adoption or execution. Kubernetes is not going to address all microservices challenges, but it does address several pain points.
Best Practices Remain
In many cases, the development and packaging of microservices destined for Kubernetes deployment is no different than a non-Kubernetes deployment. Non-Kubernetes deployments include bare metal servers, virtual machines, and containerized applications. Applications already packaged for containerized deployment make the step to adopt Kubernetes-managed microservices straightforward.
1. All key microservices patterns, development, and deployment best practices are applied.
2. Application tech stacks and components are unchanged.
3. Continuous integration/continuous delivery (deployment) systems remain intact.
4. Operating system platforms and versions can be tightly controlled.
Differences
The differences between Kubernetes and non-Kubernetes microservices architectures focus less on the task performed by the microservices and more on the deployment of non-functional requirements. Satisfying non-functional requirements is not a new concept introduced by Kubernetes or even by a microservices architecture. However, through a combination of leveraging the services offered by Kubernetes itself as well as defining cross-cutting application support services, supporting many nonfunctional requirements becomes transparent to an application. The following are two examples.
Kubernetes Ingress
A Kubernetes Ingress is an example of a configurable service that auto-configures external access to microservices. When a microservice is deployed, it can define whether and how it is to be externally accessed. If a microservice specifies that it is to be externally accessible, the Ingress services within the Kubernetes cluster automatically configure external access, including details such as virtual host definitions and SSL certificates.
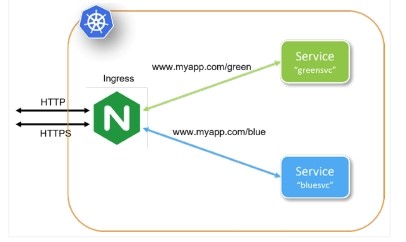
Figure 1: An Ingress definition supporting two services
Here, a Kubernetes Ingress accepts HTTP(S) requests external to the Kubernetes cluster and, based on the request path, routes requests to specific services within the cluster.
Operators
Kubernetes Operators are a Cloud Native Computing Foundation (CNCF) specification outlining a pattern that supports cross-cutting application services. They behave similarly to a Kubernetes Ingress in that a service is auto-configured based on application specification. The primary difference is that Kubernetes Operators present an abstraction where any type of service is automatically configured to extend the behavior of a Kubernetes cluster. There are Kubernetes Operators that connect applications to logging and metrics systems with the application knowing little of the specifics regarding those systems' implementation. There are also Kubernetes Operators that will build and deploy complete database instances.
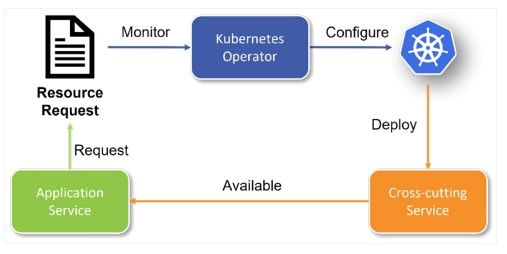
Figure 2: Kubernetes Operator flow
In the diagram above, an application requests that a service be made available for its use. The Kubernetes Operator monitors and watches for requests. When a request is made, the Kubernetes Operator instructs the Kubernetes cluster to deploy or configure a cross-cutting service specific to the application's request.
Abstractions
Kubernetes provides and supports abstractions over many systems required to satisfy non-functional components. Successful Kubernetes microservices architectures are comprehensive beyond application architecture, considering a strategy to not only address interoperability across microservices but coordination with common services.
Applying Kubernetes Constructs to a Microservices Architecture
Kubernetes deploys container-based applications; this implies
that an artifact of a microservice build and packaging process is a Docker (or
suitable alternative) image. In Kubernetes, the basic deployment unit for an
image is a Pod. Often
there is a one-to-one relationship between a deployed image and a Pod. However,
Kubernetes Pods can support multiple deployed images within a single Pod. While the
deployed containers do not share a file system, they can reference each other
using localhost.
Within a Kubernetes cluster, deployed Pods can provide their services to other Pods. This is like a deployed microservice on bare metal or a virtual machine, although this deployment doesn't provide access to the Pod's service from an external resource, high availability, or scalability. As discussed, Kubernetes helps applications meet non-functional requirements. A general rule of thumb is when "-ility" is used to describe a function, it often means a non-functional requirement. Using high availability and scalability as examples, Kubernetes provides these with relative ease. There are a few Kubernetes constructs that support these functions. Two are presented here: Services and Deployments.
Kubernetes provides a construct called a Service. A Kubernetes Service specifies ports that a microservice wishes to expose and how they are to be exposed. Services provide two powerful features. First, a Kubernetes Service integrates with the internal Kubernetes DNS service to provide a consistent hostname by which the microservices are accessed within the Kubernetes cluster. In addition, if there are multiple instances of the same microservice Pod, a Kubernetes Service can act as a load balancer across the Pod instances, providing high availability.
While Pod instances can be individually deployed, manually monitoring their status is impractical. A common pattern for adding automation to Pod "-ilities" is Kubernetes Deployments. Kubernetes Deployments specify details surrounding Pod definitions and provide several features that support the production deployment of microservices, including:
1. The number of replicas to be maintained
2. Updating the state of declared Pods
3. Rollback to earlier versions
4. Scaling up or down the number of Pods
With Pod, Service, and Deployment definitions, a solid microservices architecture is in place. In this microcosm, one piece remains — that is, auto-scaling. With Deployments, scalability is available, but like direct Pod deployments, they are manually controlled. The final component to this architectural pattern is using a HorizontalPodAutoscaler to automatically scale the number of Pod instances based on certain criteria (e.g., CPU usage).
This example demonstrates how Kubernetes can take any containerized microservice and, using Kubernetes constructs, satisfy the critical non-functional requirements that most applications require. Assembling the patterns discussed here, the following diagram presents a high-level visual of a Kubernetes microservices deployment pattern:
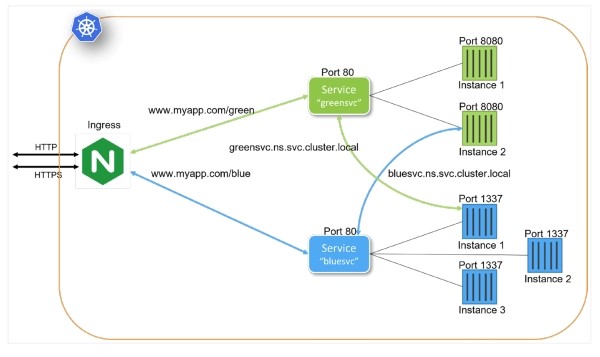
Figure 3: Putting it all together
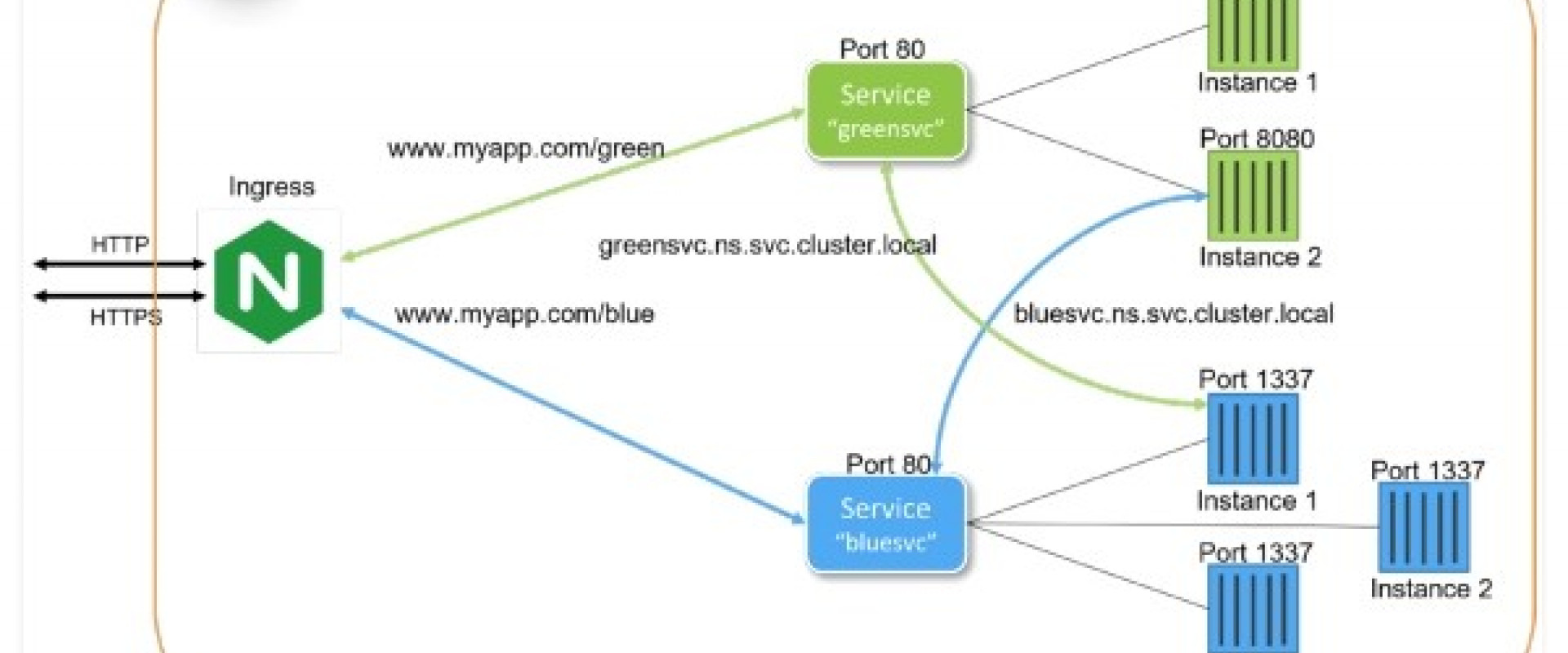
The diagram portrays two microservices, "greensvc" and "bluesvc." Each microservice utilizes a Kubernetes Service to expose its functionality. In addition to providing high availability by load balancing multiple Kubernetes Pods per microservice, the Kubernetes Service maps expose Pod ports to port 80. The definition of a Kubernetes Service also creates DNS entries internal to the Kubernetes cluster (greensvc.ns.cluster.local and bluesvc.ns.cluster.local) that can allow microservices to interoperate. Both microservices are exposed outside the Kubernetes cluster through a Kubernetes Ingress. The configured ingress routes incoming requests to their respective services.
Microservices Deployment Patterns
Kubernetes provides many constructs and abstractions to support service and application Deployment. While applications differ, there are foundational concepts that help drive a well-defined microservices deployment strategy. Well-designed microservices deployment patterns play into an often-overlooked Kubernetes strength. Kubernetes is independent of runtime environments. Runtime environments include Kubernetes clusters running on cloud providers, in-house, bare metal, virtual machines, and developer workstations. When Kubernetes Deployments are designed properly, deploying to each of these and other environments is accomplished with the same exact configuration.
In grasping the platform independence offered by Kubernetes, developing and testing the deployment of microservices can begin with the development team and evolve through to production. Each iteration contributes to the overall deployment pattern. A production deployment definition is no different than a developer's workstation configuration. This pattern provides a level of validation that is difficult to reproduce in any previous pattern and can lead to rapid maturity of an application's delivery cycle.
The Kubernetes ecosystem offers tools that support these patterns. The most predominant tool is Helm, which orchestrates the definition, installation, and upgrade of Kubernetes applications. It's through tools such as Helm that the same deployment definition can be executed across multiple runtime environments by simply supplying a set of parameters specific to a runtime environment. These parameters don't change the deployment pattern; rather, they configure the deployment pattern to meet the runtime environment (e.g., configuring the amount of memory to allocate to a process).
Microservices Deployment in Kubernetes Makes Sense
Deploying microservices in Kubernetes is an evolution of microservices architectures. Kubernetes addresses many pain points and challenges in developing and deploying microservices-based applications. Being an evolution implies that it's not a revolution. It's not a rewrite. When designing microservices, in many ways, Kubernetes addresses the question that needs to be answered. Rather than waiting, good Kubernetes design and deployment patterns encourage tackling non-functional requirements early in the development process, leading to an application that will mature much faster.
Whether it's Kubernetes or a different deployment platform, the same issues that need to be considered will need to be addressed upfront or later. In software engineering, it's almost always best to consider issues upfront. Kubernetes directly helps in addressing many microservices architectures and deployment challenges.
We Provide consulting, implementation, and management services on DevOps, DevSecOps, Cloud, Automated Ops, Microservices, Infrastructure, and Security
Services offered by us: https://www.zippyops.com/services
Our Products: https://www.zippyops.com/products
Our Solutions: https://www.zippyops.com/solutions
For Demo, videos check out YouTube Playlist: https://www.youtube.com/watch?v=4FYvPooN_Tg&list=PLCJ3JpanNyCfXlHahZhYgJH9-rV6ouPro
If this seems interesting, please email us at [email protected] for a call.
Relevant Blogs:
3 Docker Desktop Extensions Every Developer Must Try
Avoiding the Kubernetes Cost Trap
Is Multi-Cloud Infrastructure the Future of Enterprises?
The Top Elastic Beanstalk Alternatives for Startups in 2022
Recent Comments
No comments
Leave a Comment
We will be happy to hear what you think about this post