Assessment of Scalability Constraints (and Solutions)

Scaling in the age of serverless and microservices is very different than it was a decade ago. Explore practical advice for overcoming scalability challenges.
Our approach to scalability has gone through a tectonic shift over the past decade. Technologies that were staples in every enterprise back end (e.g., IIOP) have vanished completely with a shift to approaches such as eventual consistency. This shift introduced some complexities with the benefit of greater scalability. The rise of Kubernetes and serverless further cemented this approach: spinning a new container is cheap, turning scalability into a relatively simple problem. Orchestration changed our approach to scalability and facilitated the growth of microservices and observability, two key tools in modern scaling.
Horizontal to Vertical Scaling
The rise of Kubernetes correlates with the microservices trend as seen in Figure 1. Kubernetes heavily emphasizes horizontal scaling in which replications of servers provide scaling as opposed to vertical scaling in which we derive performance and throughput from a single host (many machines vs. few powerful machines).
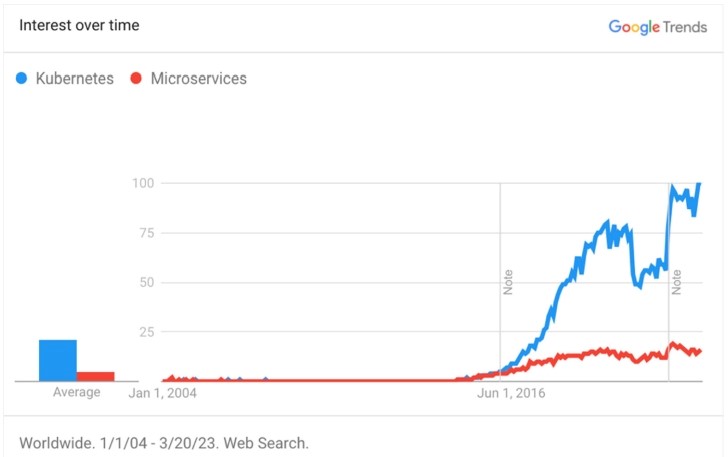
Figure 1: Google Trends chart showing correlation between Kubernetes and microservice
(Data source: Google Trends )
In order to maximize horizontal scaling, companies focus on the idempotency and statelessness of their services. This is easier to accomplish with smaller isolated services, but the complexity shifts in two directions:
- Ops – Managing the complex relations between multiple disconnected services
- Dev – Quality, uniformity, and consistency become an issue.
Complexity doesn't go away because of a switch to horizontal scaling. It shifts to a distinct form handled by a different team, such as network complexity instead of object graph complexity. The consensus of starting with a monolith isn't just about the ease of programming. Horizontal scaling is deceptively simple thanks to Kubernetes and serverless. However, this masks a level of complexity that is often harder to gauge for smaller projects. Scaling is a process, not a single operation; processes take time and require a team.
A good analogy is physical traffic: we often reach a slow junction and wonder why the city didn't build an overpass. The reason could be that this will ease the jam in the current junction, but it might create a much bigger traffic jam down the road. The same is true for scaling a system — all of our planning might make matters worse, meaning that a faster server can overload a node in another system. Scalability is not performance!
Scalability vs. Performance
Scalability and performance can be closely related, in which case improving one can also improve the other. However, in other cases, there may be trade-offs between scalability and performance. For example, a system optimized for performance may be less scalable because it may require more resources to handle additional users or requests. Meanwhile, a system optimized for scalability may sacrifice some performance to ensure that it can handle a growing workload.
To strike a balance between scalability and performance, it's essential to understand the requirements of the system and the expected workload. For example, if we expect a system to have a few users, performance may be more critical than scalability. However, if we expect a rapidly growing user base, scalability may be more important than performance. We see this expressed perfectly with the trend towards horizontal scaling. Modern Kubernetes systems usually focus on many small VM images with a limited number of cores as opposed to powerful machines/VMs. A system focused on performance would deliver better performance using few high-performance machines.
Challenges of Horizontal Scale
Horizontal scaling brought with it a unique level of problems that birthed new fields in our industry: platform engineers and SREs are prime examples. The complexity of maintaining a system with thousands of concurrent server processes is fantastic. Such a scale makes it much harder to debug and isolate issues. The asynchronous nature of these systems exacerbates this problem. Eventual consistency creates situations we can't realistically replicate locally, as we see in Figure 2. When a change needs to occur on multiple microservices, they create an inconsistent state, which can lead to invalid states.
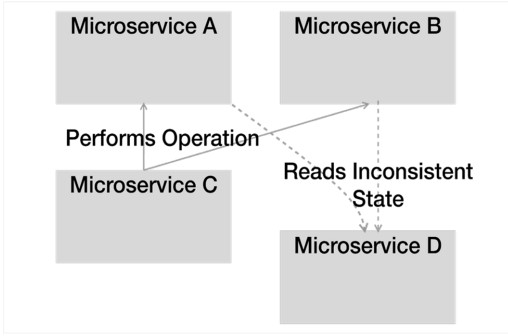
Figure 2: Inconsistent state may exist between wide-sweeping changes
Typical solutions used for debugging dozens of instances don't apply when we have thousands of instances running concurrently. Failure is inevitable, and at these scales, it usually amounts to restarting an instance. On the surface, orchestration solved the problem, but the overhead and resulting edge cases make fixing such problems even harder.
Strategies for Success
We can answer such challenges with a combination of approaches and tools. There is no "one size fits all," and it is important to practice agility when dealing with scaling issues. We need to measure the impact of every decision and tool, then form decisions based on the results.
Observability serves a crucial role in measuring success. In the world of microservices, there's no way to measure the success of scaling without such tooling. Observability tools also serve as a benchmark to pinpoint scalability bottlenecks, as we will cover soon enough.
Vertically Integrated Teams
Over the years, developers tended to silo themselves based on expertise, and as a result, we formed teams to suit these processes. This is problematic. An engineer making a decision that might affect resource consumption or might impact such a tradeoff needs to be educated about the production environment.
When building a small system, we can afford to ignore such issues. Although as scale grows, we need to have a heterogeneous team that can advise on such matters. By assembling a full-stack team that is feature-driven and small, the team can handle all the different tasks required. However, this isn't a balanced team. Typically, a DevOps engineer will work with multiple teams simply because there are far more developers than DevOps.
This is logistically challenging, but the division of work makes more sense in this way. As a particular microservice fails, responsibilities are clear, and the team can respond swiftly.
Fail-Fast
One of the biggest pitfalls to scalability is the fail-safe approach. Code might fail subtly and run in non-optimal form. A good example is code that tries to read a response from a website. In a case of failure, we might return cached data to facilitate a failsafe strategy. However, since the delay happens, we still wait for the response. It seems like everything is working correctly with the cache, but the performance is still at the timeout boundaries.
This delays the processing. With asynchronous code, this is hard to notice and doesn't put an immediate toll on the system. Thus, such issues can go unnoticed. A request might succeed in the testing and staging environment, but it might always fall back to the fail-safe process in production.
Failing fast includes several advantages for these scenarios:
- It makes bugs easier to spot in the testing phase. Failure is relatively easy to test as opposed to durability.
- A failure will trigger fallback behavior faster and prevent a cascading effect.
- Problems are easier to fix as they are usually in the same isolated area as the failure.
API Gateway and Caching
Internal APIs can leverage an API gateway to provide smart load balancing, caching, and rate limiting. Typically, caching is the most universal performance tip one can give. But when it comes to scale, failing fast might be even more important. In typical cases of heavy load, the division of users is stark. By limiting the heaviest users, we can dramatically shift the load on the system. Distributed caching is one of the hardest problems in programming. Implementing a caching policy over microservices is impractical; we need to cache an individual service and use the API gateway to alleviate some of the overhead.
Level 2 caching is used to store database data in RAM and avoid DB access. This is often a major performance benefit that tips the scales, but sometimes it doesn't have an impact at all. Stack Overflow recently discovered that database caching had no impact on their architecture, and this was because higher-level caches filled in the gaps and grabbed all the cache hits at the web layer. By the time a call reached the database layer, it was clear this data wasn't in cache. Thus, they always missed the cache, and it had no impact. Only overhead.
This is where caching in the API gateway layer becomes immensely helpful. This is a system we can manage centrally and control, unlike the caching in an individual service that might get polluted.
Observability
What we can't see, we can't fix or improve. Without a proper observability stack, we are blind to scaling problems and to the appropriate fixes. When discussing observability, we often make the mistake of focusing on tools. Observability isn't about tools — it's about questions and answers.
When developing an observability stack, we need to understand the types of questions we will have for it and then provide two means to answer each question. It is important to have two means. Observability is often unreliable and misleading, so we need a way to verify its results. However, if we have more than two ways, it might mean we over-observe a system, which can have a serious impact on costs.
A typical exercise to verify an observability stack is to hypothesize common problems and then find two ways to solve them. For example, a performance problem in microservice X:
- Inspect the logs of the microservice for errors or latency — this might require adding a specific log for coverage.
- Inspect Prometheus metrics for the service.
Tracking a scalability issue within a microservices deployment is much easier when working with traces. They provide a context and a scale. When an edge service runs into an N+1 query bug, traces show that almost immediately when they're properly integrated throughout.
Segregation
One of the most important scalability approaches is the separation of high-volume data. Modern business tools save tremendous amounts of meta-data for every operation. Most of this data isn't applicable for the day-to-day operations of the application. It is meta-data meant for business intelligence, monitoring, and accountability. We can stream this data to remove the immediate need to process it. We can store such data in a separate time-series database to alleviate the scaling challenges from the current database.
Conclusion
Scaling in the age of serverless and microservices is a very different process than it was a mere decade ago. Controlling costs has become far harder, especially with observability costs which in the case of logs often exceed 30 percent of the total cloud bill. The good news is that we have many new tools at our disposal — including API gateways, observability, and much more.
By leveraging these tools with a fail-fast strategy and tight observability, we can iteratively scale the deployment. This is key, as scaling is a process, not a single action. Tools can only go so far and often we can overuse them. In order to grow, we need to review and even eliminate unnecessary optimizations if they are not applicable.
We Provide consulting, implementation, and management services on DevOps, DevSecOps, DataOps, Cloud, Automated Ops, Microservices, Infrastructure, and Security
Services offered by us: https://www.zippyops.com/services
Our Products: https://www.zippyops.com/products
Our Solutions: https://www.zippyops.com/solutions
For Demo, videos check out YouTube Playlist: https://www.youtube.com/watch?v=4FYvPooN_Tg&list=PLCJ3JpanNyCfXlHahZhYgJH9-rV6ouPro
If this seems interesting, please email us at [email protected] for a call.
Recent Comments
No comments
Leave a Comment
We will be happy to hear what you think about this post