Data Platform: The Successful Paths

Read this post about how having several products in a Data Platform increases solution complexity, but also gives flexibility.
Introduction
I've been working as Solution Architect for many years, and I've seen the same mistakes very often. Usually, companies want to evolve their data platform because the current solution doesn't cover their needs, which is a good reason. But many times they start from the wrong starting point:
- Identify the requirements and the to-be solution but forget the retrospective step of the current solution.
- Identify certain products as the main problems. Often this involves choosing another product as the magic solution to resolve these problems.
- Identify technological silos but no knowledge silos, therefore do not support enough the data governance solutions.
- To not plan thoroughly a coexistence plan between the current solution and the new one. The migrations never end, and the legacy products never switch off.
I think the reasons are simple, and at the same time are very difficult to change:
- In the end, we are people and usually, we don't like to hear what we are doing wrong. We do not apply enough critical thinking.
- The culture of making mistakes is bad. Sometimes, this kind of analysis can overcome the feeling of blame.
- The retrospective steps require a lot of effort and time. At this moment, our society is in a culture of impatience and instant gratification.
Making mistakes and identifying them are all part of the learning process. It is a good indicator that we are working to improve and evolve our solutions. But we have to analyze deeply and understand the reasons (what, why, etc.) to avoid making the same mistakes every time.
There are no magical data products, or at least, I don't know them. A global Data Platform has many use cases, and not all of them can be resolved by the same data product. I remember when RDBMS Databases were the solution for all use cases. So many companies would invest a lot of money and effort in very big RDMBS (OLTP/OLAP) Databases such as Teradata, Oracle Exadata, IBM, or DB2. After those, came the Big Data ecosystem and NoSQL, and again everybody began to design Big Data Lake even as Data Warehouse using solutions such as Impala and Hive. Many of these solutions failed because they were only technological changes following the trends of the moment, but almost nobody had analyzed the causes:
- How many workloads do we have? Which are working fine and which are not?
- What are the causes? Could the data model be a problem?
- How are we consuming the data?
- Is latency the problem? Where is the latency gap?
- Are we following an automation paradigm?
- Is our architecture very complex?
Today, we are in a more complex scenario. There are more data products (and marketing) joined with a new cloud approach. Cloud requires, more than ever, to change our culture, vision, and methodology.
Having several products in our Data Platform increases the solution complexity in many terms such as operations, coexistence, or integrations, but at the same time gives us the flexibility to provide different qualities and also avoid locking vendor scenarios. We have to take advantage of the benefits of the cloud. One of them is to reduce operational costs and effort that allows for providing a better solution in terms of the variety of services.
Logical Data Fabric and Data Virtualization
This architecture provides a single layer that enables the users and applications access to the data and uncouples the location of the data and the specific technology repository product. This approach improves the data integration experience for users by allowing us to evolve the data repositories layer without impacting the operation of the systems. This capacity also is the foundation for making our BI layer more agile. Logic Data Fabric helps us adapt quickly to changing business needs, allowing us to add new technology capabilities, reducing integration effort and time to market.
Today, Hybrid Multi-Cloud solutions are generating a lot of interest. Companies like Denodo have been working for many years to provide solutions focused on data fabric and data virtualization.
Joining Logic Data Fabric with Data Virtualization is a powerful tool, but can become so complex and concentrate all logic in one place. It is something to take into account.
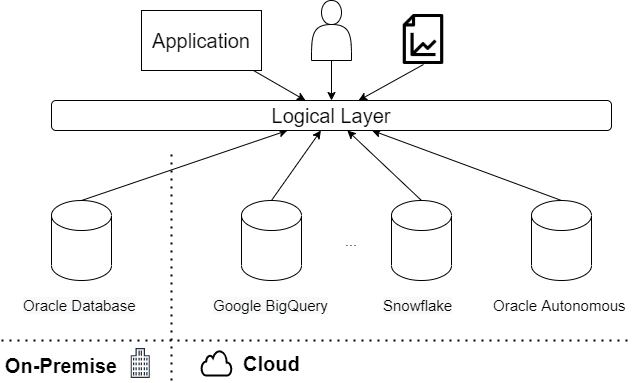
Currently, one of the most common scenarios is to migrate On-Premise solutions to Cloud or Multi-Cloud solutions. In these cases, data migration and data integration are some of the challenges.
- Migrate the data from on-premise databases to the new cloud data platform.
- Integrate the current solution with the new data platform.
- Verify the quality of data.
These are not easy tasks to perform, and we have to do it every time we change one of our data repositories. One of the keys to success is to provide a logic data layer that provides the data from different sources based on some criteria.
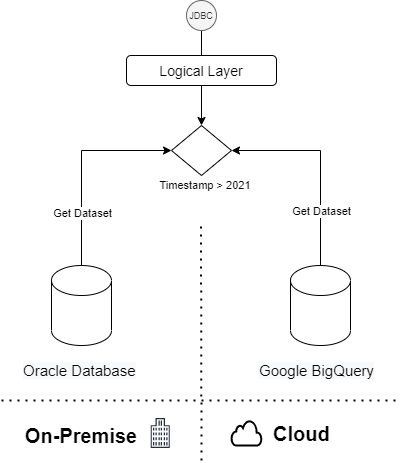
These capabilities provide us with a lot of flexibility to design our migration and coexistence strategies.
For example, we can start replicating the same dataset on both platforms (On-Premise and Cloud). The logic layer will retrieve the dataset from one of the data repositories based on timestamps.
Avoid Coupling All Logic in the Data Repository
In the last few years, there has been a lot of effort to uncouple the data and the logic into different layers. In my opinion, this is the right way to go.
Having the logic and the data in the same layer involve problems such as silos, monoliths, locking vendor, or performance problems. Often the data repository is the most expensive layer. I remember employing a lot of effort to get out miles of PL/SQL for other more cost-efficient distributed solutions.
I think that many times cloud data solutions provide unrealistic scalability. Of course, we can scale up our solution but at what cost? Currently, some development teams are less focused on process optimization because, unlike On-Premise, in the cloud, it can scale without limits. The problems are the costs and many times when coming out requires a lot of effort and time to solve.
We should not forget that distributed databases existed before the cloud. Cloud solutions provide us better performance in many cases, pay as you go, fewer operation tasks, and scale resources only when we need them. But in many cases is the same technology that we have on our On-Premise.
I see again how many teams are getting back to applying the same approach massively as years ago. It doesn't mean that we can not use streams/tasks in Snowflake or PLSQL in Oracle Autonomous Databases, but also not use them as a global approach and for all the use cases. We run the risk that we will build a monolith again.
Don't get me wrong: Snowflake, Big Query, Oracle Autonomous Database, and other new data products are great products, with great functionalities but the key is to use them correctly inside of our data strategy.
Avoid Building a Sandcastle
A poor performance in terms of latency or data processing concurrency is one of the reasons to design and build a new data platform. We have to avoid creating dependencies between the current solution and the new one. Because as we know, "A Chain is As Strong As The Weakest Link".
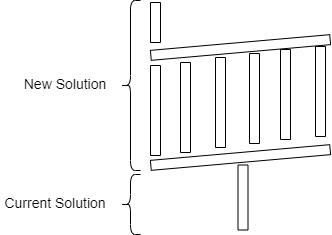
A common scenario is to design the new solution over the current solution which implies a strong dependency between them. We will propagate the problems from one platform to another and increase the risk of impact on the current solution. For instance, many times the data source of the new data platform is the current one:
- If we have a problem with the latency of the data, it is not a good solution to add a new step in the data flow. This approach will increase the latency problem.
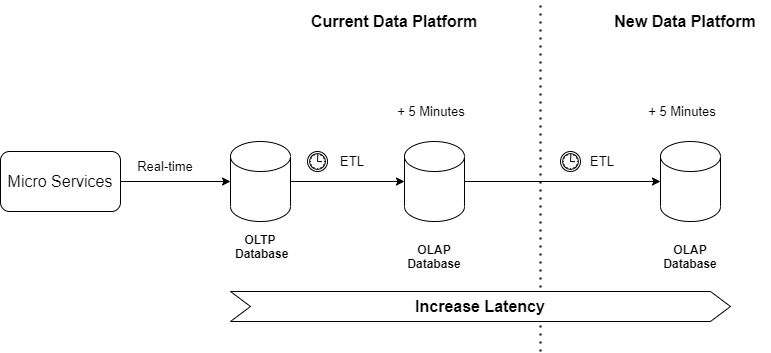
- If we have a problem with the availability and/or performance of the current solution, we are going to increase this problem because we are adding a new consumer. Replication of data can involve a heavy load on the database systems.
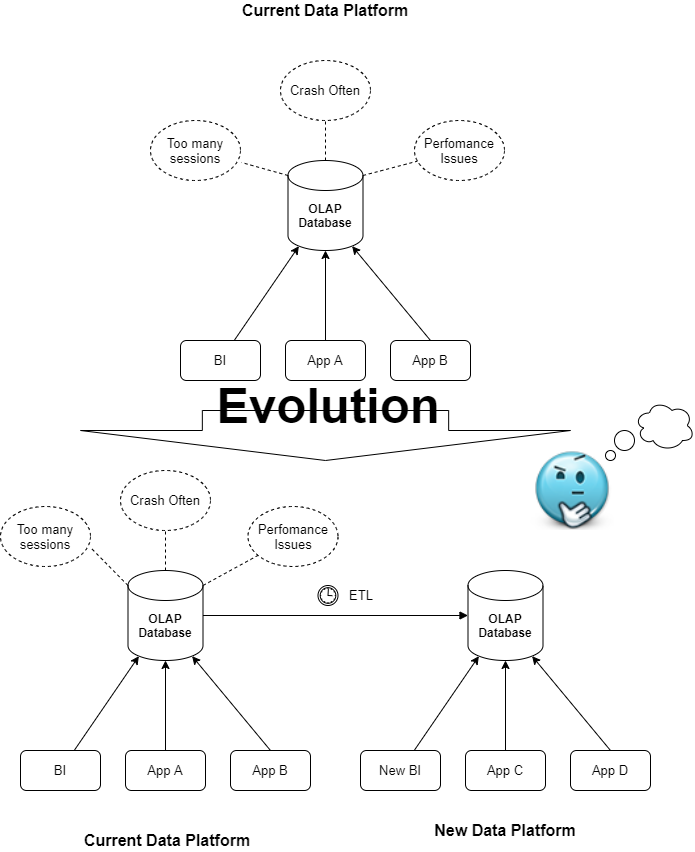
Another common scenario is to change the data repository but keep the same ingestion approach and data model. In many companies, the ETL is the main replication process and often involves performance or data quality issues. It doesn't matter that we change the data repository, because replication based on ETL always involves the same problems.
Conclusion
Designing a successfully new Data Platform usually comes from understanding why we are here at this point. Knowing the past is important for understanding the present, designing the future, and avoiding making the same mistakes again.
New technological improvements and architectures require a change in the way we work and think. As a team, we must evolve to avoid applying the same methodologies from On-Premise environments in Cloud. The team culture and architecture patterns are more important than the products.
In the beginning, it could seem like a great strategy to build a new solution on top of something that is currently not working from of point of view of timing requirements. Often, it will generate more issues, consuming team effort and generating team and user dissatisfaction.
We ZippyOPS, Provide consulting, implementation, and management services on DevOps, DevSecOps, Cloud, Automated Ops, Microservices, Infrastructure, and Security
Services offered by us: https://www.zippyops.com/services
Our Products: https://www.zippyops.com/products
Our Solutions: https://www.zippyops.com/solutions
For Demo, videos check out YouTube Playlist: https://www.youtube.com/watch?v=4FYvPooN_Tg&list=PLCJ3JpanNyCfXlHahZhYgJH9-rV6ouPro
Relevant blogs:
What Is a Data Reliability Engineer, and Do You Really Need One?
How to Develope a Successful Business Intelligence (BI) Strategy
Big Data and Cloud Computing - A Perfect Blend to Manage Bulk Data
10 Robust Enterprise-Grade ELT Tools To Collect Loads of Data
Recent Comments
No comments
Leave a Comment
We will be happy to hear what you think about this post