How to Successfully Leverage AI in Your Automated Kubernetes Monitoring
In this article, we’re going to take a look at the best methods available to you to leverage AI in your automated Kubernetes monitoring.
Organizations are continuously seeking to grow, have better customer relationships, and provide user experiences that edge out rivals, digital acceleration is gathering pace. The IT industry, in particular, and its role in large-scale production environments has grown exponentially complex, with companies investing in AI solutions and increasingly preoccupied with questions such as: “what is hyper-automation?”
Monitoring technology gives visibility into these highly disseminated IT environments. AI monitoring systems, in turn, use more components that help streamline complexities and usher in a shift from reactive to proactive decision-making. Throughout this article, we’re going to take a look at the best methods available to you in leveraging AI in your automated Kubernetes monitoring.
Let’s get down to it.
Kubernetes and Cloud Container Orchestration
Kubernetes (K8s) provides a portable open-source solution designed to monitor containerized workload. Still, for all of the appreciable benefits it offers for container management, it’s not a total solution on its own. It functions more like an integral piece of your larger IT infrastructure ecosystem.
Containers have become the framework of choice for deploying microservices-based applications at scale and Kubernetes has become the favored platform for managing them. Given the ease with which these dynamic platforms can automate web server provisioning, organizations must adopt an AI-driven approach to infrastructure monitoring equal to this level of complex digital transformation.
Manual Handling
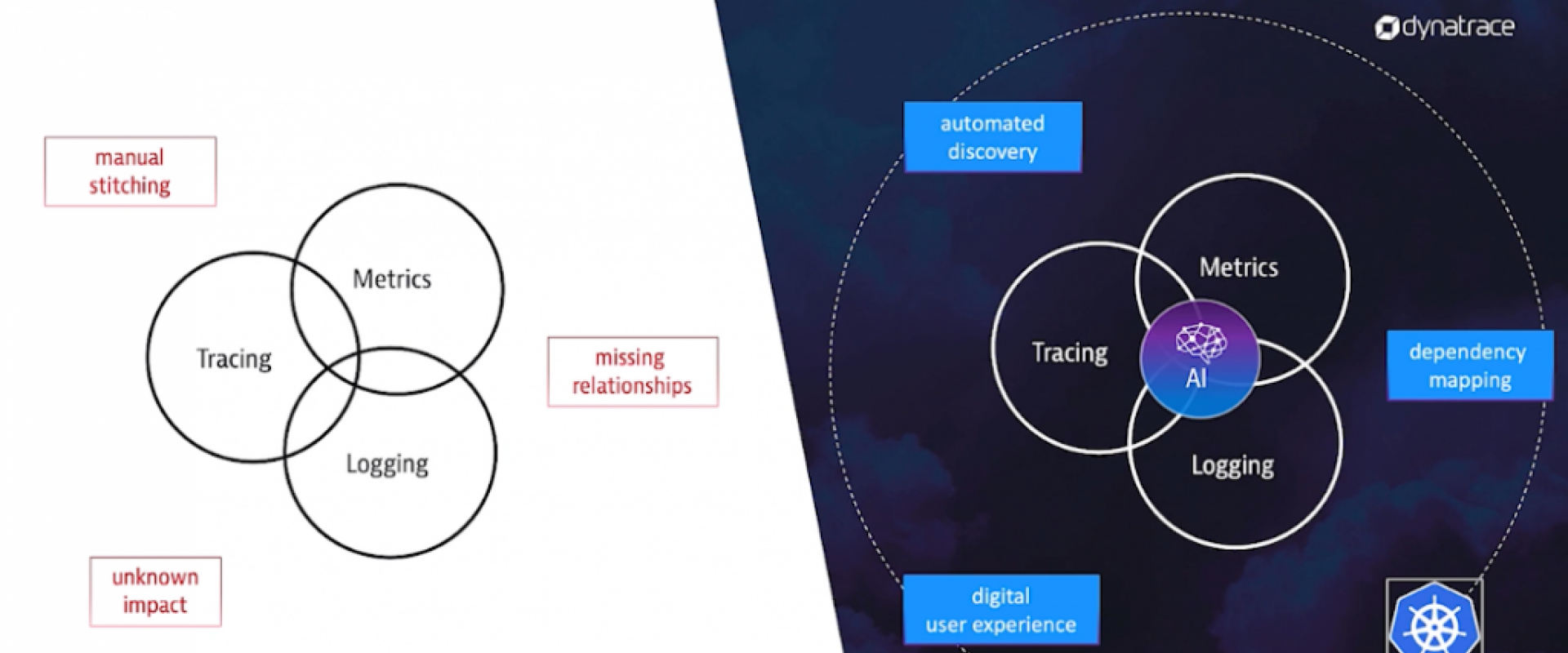
The complexity and elasticity of Kubernetes-based cloud platforms are that they deliver more agile IT environments. Yet, a consequence is that manual observability is inadequate at the task of capturing a comprehensive picture of what’s happening in your multi-cloud environment and underlying infrastructure.
Manual observability and configuration for containers, microservices, and Kubernetes, are not resource-effective. For one thing, IT teams can get mired in the sheer complexity.
The limits of traditional monitoring mean that without AI, you end up with little insight into the infrastructure components and interdependencies that are otherwise a rich source of digital business analytics. Without AI, you’ll lack observability of important information about the building blocks of your system.
Having a vast number of containers talking to each other in your organization is no failsafe against blind spots. So you need to get a handle on non-performing code or single out exceptions when they happen by using details about specific users, transactions, their context, and metadata.
Containing Challenges
Such information is essential in gaining a superior understanding of how your organization is performing. This kind of Kubernetes monitoring requires end-to-end observability that goes beyond metrics, logs, and traces, and speaks to the context in which exceptions happen and the user impact.
Without a complete understanding of the interactions of microservices, worker nodes, user sessions, and the dependencies they rely on, organizations are hamstrung when trying to address root causes of slowdowns or issues. Sure, IT teams can manually stitch up connective constructs by tracing and logging interactions.
Unknown Impact
The biggest downside of manual solutions is the lack of full-stack visibility into container interactions which leaves you in the dark on the impact of issues on your end-users. From an increase in response time to a failure rate, you need to understand how end-users are interacting with your microservices.
Without a complete picture of your environment, your unchecked system degradations could lead to a slew of repercussions for your business. The result? A massive drain on your IT productivity.
Bridging the Observability Gap
Let's take a more fine-grained look into how you can leverage AI. Such advanced observability in the form of automatic code-level insights is game-changing. By freeing up your team from the time-consuming tedium of manual work to refocus on the mission-critical tasks which add value and drive innovation, you will increase organizational productivity no end.
Developers and Kubernetes platform operators need to be empowered to identify insights and make the changes equivalent to a dynamic environment comprising hundreds or thousands of containers and microservices in production.
Tip: Optimize in conjunction with a strategic quality assurance process to prioritize service quality.
Eyes Wide Open
Enable your team to see into every component in your Kubernetes infrastructure layer by using an AI-driven approach to your automated monitoring. This kind of advanced insight and level of control would be show-stoppingly challenging for teams to obtain manually. It also allows you to analyze the continuous impact of every container, pod, node, cluster, and microservice on your customers and the business.
Map
AI solutions can improve your Kubernetes monitoring by providing end-to-end dependency mapping and a multidimensional overview of all the connections between containers in addition to incoming and outgoing interactions on the vertical stack.
Measure
AI monitoring also helps you measure the impact of your services at scale. By highlighting hot spots and providing in-depth visibility of transactions through different technologies and infrastructure components, AI allows you to optimize specific endpoints and break down silos.
Manage
Kubernetes monitoring enables you to quantify how users access your services, as well as understand how your site performs in terms of sessions, conversions, and metrics under different circumstances.
Stay Alert
Finally, here are a few best practice tips on how to harness AI in automating your alerts:
1) To detect applications quickly, focus on tracking API metrics such as call error, request rate, and latency in your microservices. Rather than use static alerts for hundreds of different APIs, use AI monitoring to perform aggregated resource pattern detection to detect anomalies and pattern changes in metrics before they tank outright.
2) Cut through the noise of monitoring individual containers. The system can learn any given Kubernetes resource metric's normal behavior and establish a baseline so that an alert isn’t delivered each time the metric peaks.
3) Track metrics related to the critical “status” and “reason” dimensions concerning your services' overall state. This way, you can parse minor hiccups from actual trends that need action.
4) Trigger anomaly alerts on the all-important high disk usage (HDU) metric.
Complex Business
How do you understand your systems? Even with automation testing in place, who watches the watchers? These are some of the questions organizations must ask as they build more complex systems and adopt new technologies in the ongoing war to manage such complexity.
Fortunately, AI-driven approaches provide an answer. Organizations that benefit from advanced oversight not only optimize everything from cost, capacity, and workloads but also diagnose potential issues at source, and glean accurate and actionable data into the interdependencies across their IT environment.
Relevant blogs:
Best Frameworks to Use for AI App Development in 2022
Top 5 AI Trends That Will Shape 2022 and Beyond
The "Onion Peel" Approach to Hyper Intelligent Automation
Top 5 Data Science, AI, And ML Trends for 2022
Recent Comments
No comments
Leave a Comment
We will be happy to hear what you think about this post