Migrating Monoliths to Microservices in Practice
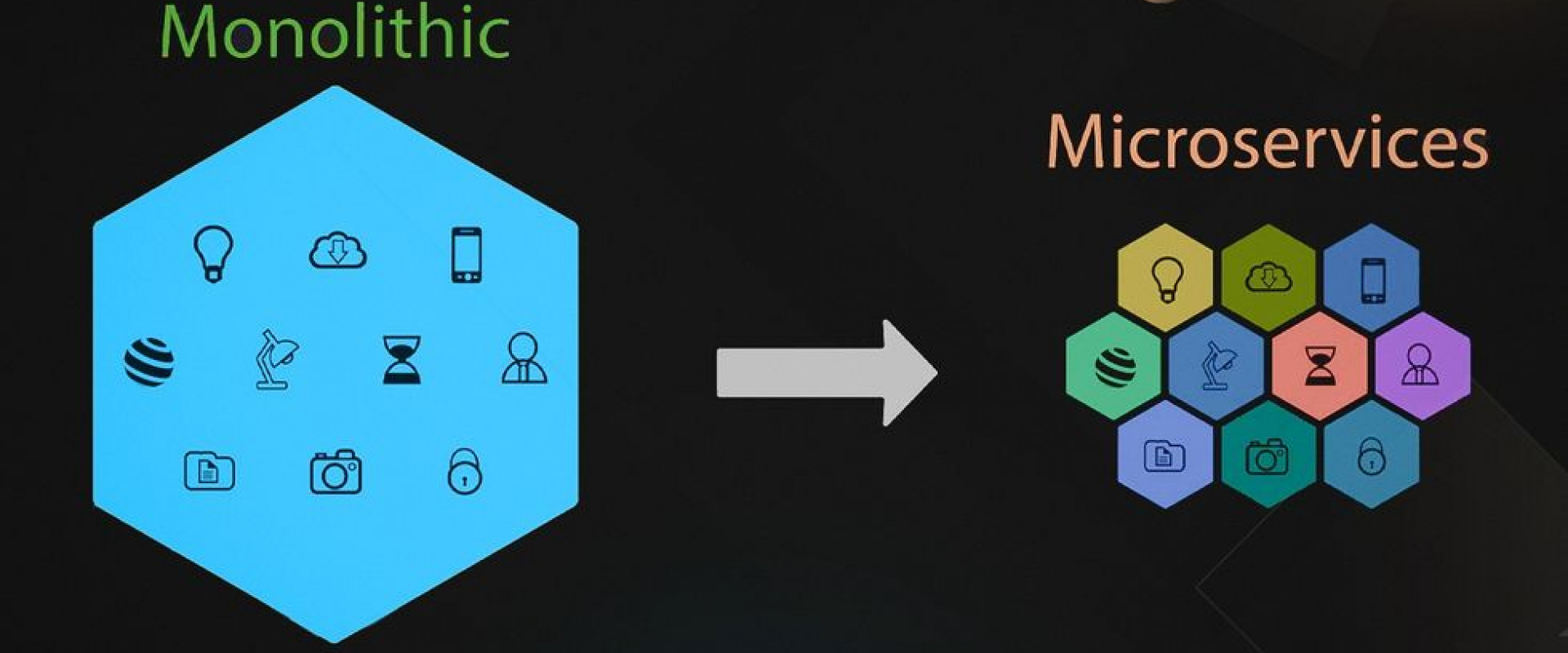
This isn't another "break down the monolith" article. This post is about making applicable decisions, measuring, and verifying the results.
There have been amazing articles on the subjects of migrating from a monolith to a microservice architecture, e.g., this is probably one of the better examples. The benefits and drawbacks of the architecture should be pretty straightforward. I want to talk about something else, though: the strategy. We build monoliths since they are easier to get started with. Microservices usually rise out of necessity when our system is already in production.
However, there are a lot of questions that arise when deciding when to do the migration or not – how do you decide the boundaries of a service? How do you verify the self-healing properties of your microservice architecture?
This is especially challenging with the distributed aspect of the service mesh. We need a view of the entire application as parts of it to break off. Our goal is to keep the conveniences we had in the legacy monolith while avoiding the tight coupling that came with the territory. In this article, I will outline some practical approaches you can use while carrying out this migration.
Decision
I’m strongly in the “start with a monolith” camp; it should be a modular monolith so we can easily break it down. There’s a myth of a monolith as a “block of interconnected code.” This is far from the case; most monoliths use the capabilities of modern programming languages (e.g., packages, modules, etc.) to separate the various pieces. Calls between the various parts of a modular monolith occur through clearly defined interfaces or event buses. My pro-monolithic applications stance probably stems from my Java background, as Java is particularly well suited to large monoliths. The point at which you would split a codebase would be radically different depending on your architecture, language, problem domain, etc.
How do you make an objective choice in this regard? When is the perfect time to start a migration to microservices?
The most important pre-requisite for a microservice architecture migration is the separation of authorization. If this isn’t separated as an external service, there’s probably no room to move forward. This is the hardest part of a microservice migration. The nice thing about this is that you can take this step while keeping the monolith architecture. If you can’t perform that migration, there’s no point in moving forward. Once this is done, there are several other factors involved:
- Team size – as your team grows, keeping cohesion is a challenge. This is something we can easily benchmark by reviewing the growth of the team. Keep an eye on the speed of onboarding and other metrics, such as time to issue resolution. These are probably the best metrics for project complexity.
- Inter-dependence – the benefit of microservices might be a hindrance if the project is deeply inter-dependent and doesn’t have clear separation lines. Some projects are inherently deeply intermingled and don’t have a clean separation of the parts. Pay attention to transactional integrity between different modules. Features such as transaction management can’t carry between microservices. If you have a system that must be reliably consistent such as a banking system that needs to be consistent at all times, the boundaries of the transaction must reside within a single service. These are the types of things that can make the migration process especially difficult.
- Testing – you can’t undergo such an effort without a significant amount of module-specific tests and a big suite of integration tests. Reviewing the test code will tell you more about your readiness than any alternative means. Can you logically test a module in isolation?
Once you have a sense of those, you can start estimating the benefit you might get from the monolith to microservices migration.
Where Do We Start?
Assuming the monolithic code is already relatively modular and supports SSO (Single Sign On), we can pick any module we want. How do we know which one will have the best return on our investment of time and effort?
Ideally, we want to target the parts that will give us the most benefit and would be easiest to migrate:
- Look at the issue tracker/version control – which module is the one most prone to failure?
- Check modularity – which module is smallest and least interdependent? Can the data be cleanly separated? – it’s best to start with lower-hanging fruit
- Profile your application – which module is most expensive and can benefit from scaling?
These things are simple enough when running locally, but often the behavior of the application in production is vastly different from its local or staging environment. In those cases, we can use developer observability tools such as a runtime line counter to evaluate usage. We need to strike a balance of benefit and utility when we choose the module to break out.
Avoiding the Tiny Monolithic Architecture
People often recite the tenants of microservices but proceed to build something that doesn’t follow the general rules. “Self-healing” is the most blatant example. Decoupling the pieces of a monolith into a microservice application is remarkably hard. We need to isolate the pieces and make sure that everything functions reasonably well at scale. Or worse, during downtime.
How can a system survive when a deployable service is down? How can we test something like that?
One of the biggest problems in such an architecture is the scale of deployment. We wrap individual services in a discovery system and API gateways, and circuit breakers to enable the healing properties. Often API gateways (and similar services) are SaaS-based solutions, but even if we deploy them ourselves, accurately replicating our production is hard. Typical complexities include coded URLs into the gateways and into the actual code. Accidentally going around the gateway and directly to the servers or underlying infrastructure. These are subtle things that are hard to detect in legacy code and large systems.
Because of this complex topology, properly testing the healing behavior is nearly impossible when working locally. Any result you get would be inaccurate because of the vastly different deployment logistics.
But we can’t bring down a production microservice just to prove a point. Right?
That’s one of the enormous benefits of microservices architecture. In the discovery code, we can add a special case that provides a “dummy” or failed microservice for a specific user. The problem is that the symptoms might be hard to verify as a “self-healing” service will appear as if it’s functioning. In that case, we can use logs or snapshots to verify that the right code is reached and the module is indeed disconnected.
E.g., we can simulate the unavailability of an API using most API gateways. Then we can check that the other services work as expected by invoking a call and verifying that a circuit breaker is triggered and results are still arriving. Our system seems healed. But maybe some user code invoked the web service directly and effectively circumvented the API gateway? How do you verify that everything works from the cache and uses the fallback that you expected?
This is where logs and snapshots come in. We can add them in the backend API and also in the broken-off service to verify that the results that we got are indeed the results from the gateway cache.
Rinse – Repeat
This process is most challenging when we break off the first microservice out of monolithic applications. As we break additional pieces, it typically becomes easier until the entire monolith is gone. But there are challenges along the way. Initially, we pick an achievable goal that is easier. As we move forward, we run into harder challenges and need to decide on boundaries for a service that might be less than ideal.
The problem is that we often need to take these steps based on intuition. But when we created the modules, we might have used logical separation instead of interdependencies. As a result, two modules might have deep dependencies and might not make sense as a microservice. Splitting them in a different location or even bundling them together might make more sense. As an example, we might have an accounting system that manages multiple accounts. A logical separation might move the code that transfers funds between accounts into a separate module. But that would make things very difficult. In an accounting system, money must arrive from one account and move to another; it can never “vanish”. As we add money to one account, we must subtract it from the other, and both need to happen in a single transaction. A trivial workaround might be to do both the deduction and the moving of the funds in a single request. However, that won’t solve the generic problem since money can be withdrawn from one account and divided into multiple accounts. Doing this in multiple small operations can cause side effects. This is doable, but personally, I would keep the core accounting logic together with the accounts system in such a case.
Some of those inter-dependencies can be inferred from the code and refactored away. Converted to messaging and asynchronous calls. Using a messaging service is one of the most effective ways to decouple. Many languages and platforms support a module barrier between the various parts. This lets us isolate an entire module from the rest of the application and limit the interaction to a narrow interface. By raising such a barrier, we can use the compiler and IDE to enforce module restrictions.
Finally
Breaking down monolithic applications is always challenging. It takes time and effort to isolate the business logic into the correct domains. The communication overhead and division of features to a specific service are the components that make the difference in such a process. There are no delivery guarantees, and testing is even harder. Production is a completely unique environment from development because of the API gateways, proxy settings, discovery, etc.
Successful migration of legacy code is seamless to the customer. For us, it changes the dynamics completely. Delivery is different, verifying that deployment is successful is far more challenging than it is with a monolithic application. The user experience is similar when everything works, but how do we verify that?
That’s where tooling comes in; we can use developer observability tooling (logs, counters, logs) to verify that even with production failures, the healing across service boundaries is still working. This is no trivial feat since the loose coupling is only the first step. Behavior during different forms of failure can only be tested in production, and we don’t want to fail just so we can make a point.
We Provide consulting, implementation, and management services
on DevOps, DevSecOps, Cloud, Automated Ops, Microservices, Infrastructure, and
Security
Services offered by us: https://www.zippyops.com/services
Our Products: https://www.zippyops.com/products
Our Solutions: https://www.zippyops.com/solutions
For Demo, videos check out YouTube Playlist: https://www.youtube.com/watch?v=4FYvPooN_Tg&list=PLCJ3JpanNyCfXlHahZhYgJH9-rV6ouPro
If this seems interesting, please email us at [email protected] for a call.
Relevant Blogs:
What to Learn First: Docker or Kubernetes?
AWS Lambda Timeout and How to Overcome It
Is Namespace-As-A-Service the Evolution of Cluster-As-A-Service?
Software as a Service: How to build a SaaS Application
Recent Comments
No comments
Leave a Comment
We will be happy to hear what you think about this post