Running Databases on Kubernetes
Is it a good idea to run stateful workloads on K8s?
You can run databases on Kubernetes because it's fundamentally the same as running a database on a VM. The biggest challenge is understanding that rubbing Kubernetes on Postgres won't turn it into Cloud SQL.
There seems to be a misconception about the features that k8s actually provides. While newcomers to k8s may expect that it can handle complex application lifecycle features out-of-the-box, it, in fact, only provides a set of cloud-native primitives (or building blocks) for you to configure and use to deploy your workflows. Any functionality outside of these core building blocks needs to be implemented somehow in additional orchestration code (usually in the form of an operator) or config.
K8s Primitives
When working with databases, the obvious concern is data persistence. Earlier in its history, k8s really shined in the area of orchestrating stateless workloads, but support for stateful workflows was limited. Eventually, primitives like StatefulSets, PersistentVolumes (PVs), and PersistentVolumeClaims (PVCs) were developed to help orchestrate stateful workloads on top of the existing platform.
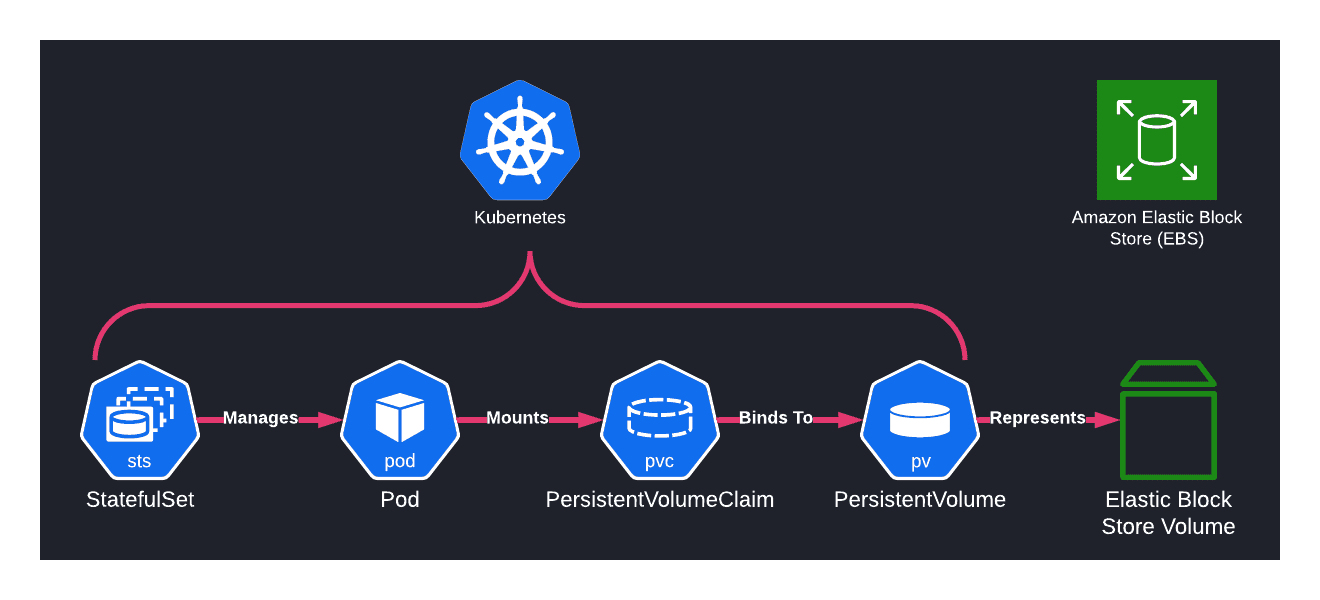
PersistentVolumes are abstractions that allow for the management of raw storage, ranging from local disk to NFS, cloud-specific block storage, and more. These work in concert with PersistentVolumeClaims that represent requests for a pod to access the storage managed by a PV. A user can bind a PVC to a PV to make an ownership claim on a set of raw disk resources encompassed by the PV. Then, you can add that PVC to any pod spec as a volume, effectively allowing you to mount any kind of persistent storage medium to a particular workload. The separation of PV and PVC also allows you to fully control the lifecycle of your underlying block storage, including mounting it to different workloads or freeing it all together once the claim expires.
StatefulSets manage the lifecycles of pods that require more stability than what exists in other primitives like Deployments and ReplicaSets. By creating a StatefulSet, you can guarantee that when you remove a pod, the storage managed by its mounted PVCs does not get deleted along with it. You can imagine how useful this property is if you're hosting a database! StatefulSets also allow for ordered deployment, scaling, and rolling updates, all of which create more predictability (and thus stability) in our workloads. This is also something that seems to go hand-in-hand with what you want out of your database's infrastructure.
What Else?
While StatefulSets, PVs, and PVCs do quite a bit of work for us, there are still many administration and configuration actions that you need to perform on a production-level database. For example, how do you orchestrate backups and restores? These can get quite complex when dealing with high-traffic databases that include functionality such as WALs. What about clustering and high availability? Or version upgrades? Are these operations zero-downtime? Every database deals with these features in different ways, many of which require precise coordination between components to succeed. Kubernetes alone can't handle this. For example, you can't have a StatefulSet automatically set up your average RDBMS in a read-replica mode very easily without some additional orchestration.
Not only do you have to implement many of these features yourself, but you also need to deal with the ephemeral nature of Kubernetes workloads. To ensure peak performance, you have to guarantee that the k8s scheduler places your pods on nodes that are already pre-tuned to run your database, with enough free resources to run it properly. If you're dealing with clustering, how are you handling networking to ensure that database nodes are able to connect to each other (ideally in the same cloud region)? This brings me to my next point...
Pets, Not Cattle
Once you start accounting for things like node performance-tuning and networking, along with the requirement to store data persistently in-cluster, all of a sudden, your infrastructure starts to grow into a set of carefully groomed pet servers instead of nameless herds of cattle. But one of the main benefits of running your application in k8s is the exact ability to treat your infrastructure like cattle instead of pets! All of the most common abstractions like Deployments, Ingresses, and Services, along with features like vertical and horizontal autoscaling, are made possible because you can run your workloads on a high-level set of infrastructure components, so you don't have to worry about your physical infrastructure layer. These abstractions allow you to focus more on what you're trying to achieve with your infrastructure instead of how you're going to achieve it.
Then Why Even Bother With K8s?
Despite these rough edges, there are plenty of reasons to want to run your database on k8s. There's no denying that k8s' popularity has increased tremendously over the past few years across both startups and enterprises. The k8s ecosystem is under constant development so that its feature set continues to expand and improve regularly. And its operator model allows end users to programmatically manage their workloads by writing code against the core k8s APIs to automatically perform tasks that would previously have to be done manually. K8s allows for easy GitOps-style management so you can leverage battle-tested software development practices when managing infrastructure in a reproducible and safe way. While vendor lock-in still exists in the world of k8s, its effect can be minimized to make it easier for you to go multi-cloud (or even swap one for another).
So what can we do if we want to take advantage of all the benefits that k8s has to offer while using it to host our database?
What Do You Need to Build an RDS on K8s?
Toward the end of the live chat, someone asked Kelsey, "what do you actually need to build an RDS on k8s?" He jokingly answered with expertise, funding, and customers. While we're certainly on the right track with these at QuestDB, I think that this can be better phrased in that you need to implement Day 2 Operations to get to what a typical managed database service would provide.
Day 2 Operations
Day 2 Operations encompass many of the items that I've been discussing; backups, restore, stop/start, replication, high availability, and clustering. These are the features that differentiate a managed database service from a simple database hosted on k8s primitives, which is what I would call a Day 1 Operation. While k8s and its ecosystem can make it very easy to install a database in your cluster, you're going to eventually need to start thinking about Day 2 Operations once you get past the prototype phase.
Here, I'll jump into more detail about what makes these operations so difficult to implement and why special care must be taken when implementing them, either by a database admin or a managed database service provider.
Stop/Start
Stopping and starting databases is a common operation in today's DevOps practices and is a must-have for any fully-featured managed database service. It is pretty easy to find at least one reason for wanting to stop and start a database. For example, you may want to have a database used for running integration tests that run on a pre-defined schedule. Or you maybe have a shared instance that's used by a development team for live QA before merging a commit. You could always create and delete database instances on-demand, but it is sometimes easier to have a reference to a static database connection string and URL in your test harness or orchestration code.
While stop/start can be automated in k8s (perhaps by simply setting a StatefulSet's replica count to 0), there are still other aspects that need to be considered. If you're shutting down a database to save some money, will you also be spinning down any infrastructure? If so, how can you ensure that this infrastructure will be available when you start the database backup? K8s provides primitives like node affinity and taints to help solve this problem, but everyone's infrastructure provisioning situation and budget are different, and there's no one-size-fits-all approach to this problem.
Backup and Restore
One interesting point that Kelsey made in his chat was that
having the ability to start an instance from scratch (moving from a stopped -> running state),
is not trivial. Many challenges need to be solved, including finding the
appropriate infrastructure to run the database, setting up network
connectivity, mounting the correct volume, and ensuring data integrity once the
volume has been mounted. In fact, this is such an in-depth topic that Kelsey
compares going from 0 -> 1 running instance to an actual backup-and-restore
test. If you can indeed spin up an instance from scratch while loading up
pre-existing data, you have successfully completed a live restore test!
Even if you have restores figured out, backups have their own complexities. K8s provides some useful building blocks like Jobs and CronJobs, which you can use if you want to take a one-off backup or create a backup schedule, respectively. But you need to ensure that these jobs are configured correctly in order to access raw database storage. Or if your database allows you to perform a backup using a CLI, then these jobs also need secure access to credentials to even connect to the database in the first place. From an end-user standpoint, you need an easy way to manage existing backups, which includes creating an index, applying data retention policies, and RBAC policies. Again, while k8s can help us build out these backup-and-restore components, a lot of these features are built on top of the infrastructure primitives that k8s provides.
Replication, HA, and Clustering
These days, you can get very far by simply vertically scaling your database. The performance of modern databases can be sufficient for almost anyone's use case if you throw enough resources at the problem. But once you've reached a certain scale or require features like high availability, there is a reason to enable some of the more advanced database management features like clustering and replication.
Once you start down this path, the amount of infrastructure orchestration complexity can increase exponentially. You need to start thinking more about networking and physical node placement to achieve your desired goal. If you don't have a centralized monitoring, logging, and telemetry solution, you're now going to need one if you want to easily diagnose issues and get the best performance out of your infrastructure. Based on its architecture and feature set, every database can have different options for enabling clustering, many of which require intimate knowledge of the inner workings of the database to choose the correct settings.
Vanilla k8s know nothing of these complexities. Instead, these all need to be orchestrated by an administrator or operator (human or automated). If you're working with production data, changes may need to happen with close-to-zero downtime. This is where managed database services shine. They can make some of these features as easy to configure as a single web form with a checkbox or two and some input fields. Unless you're willing to invest the time into developing these solutions yourself, or leverage existing open-source solutions if they exist, sometimes it's worth giving up some level of control for automated expert assistance when configuring a database cluster.
Orchestration
For your Day 2 Operations to work as they would in a managed database service such as RDS, they need to not just work but also be automated. Luckily for us, there are several ways to build automation around your database on k8s.
Helm and YAML Tools Won't Get Us There
Since k8s configuration is declarative, it can be very easy to
get from 0 -> 1 with traditional YAML-based tooling like Helm or cdk8s. Many
industry-leading k8s tools install into a cluster with a simple helm
install or kubectl apply command.
These are sufficient for Day 1 Operations and non-scalable deployments. But as soon as you start to move into more vendor-specific Day 2 Operations that require more coordination across system components, the usefulness of traditional YAML-based tools starts to degrade quickly since some imperative programming logic is required.
Provisioners
One pattern that you can use to automate database management is
a provisioner process. We've even used this approach to build v1 of our managed
cloud solution. When a user wants to make a change to an existing database's
state, our backend sends a message to a queue that is eventually picked up by a
provisioner. The provisioner reads the message, uses its contents to determine
which actions to perform on the cluster, and performs them sequentially. Where
appropriate, each action contains a rollback step in case of a kubectl
apply error to leave the infrastructure in a predictable state.
Progress is reported back to the application on a separate gossip queue,
providing almost-immediate feedback to the user on the progress of each state
change.
While this has grown to be a powerful tool for us, there is another way to interact with the k8s API that we are now starting to leverage...
Operators
K8s has an extensible Operator pattern that you can use to manage your own Custom Resources (CRs) by writing and deploying a controller that reconciles your current cluster state into its desired state, as specified by CR YAML spec files that are applied to the cluster. This is also how the functionality of the basic k8s building blocks are implemented, which just further emphasizes how powerful this model can be.
Operators have the ability to hook into the k8s API server and listen for changes to resources inside a cluster. These changes get processed by a controller, which then kicks off a reconciliation loop where you can add your custom logic to perform any number of actions, ranging from simple resource existence to complex Day 2 Operations. This is an ideal solution to our management problem; we can offload much of our imperative code into a native k8s object, and database-specific operations appear to be as seamless as the standard set of k8s building blocks. Many existing database products use operators to accomplish this, and more are currently in development (see the Data on Kubernetes community for more information on these efforts).
As you can imagine, coordinating activities like backups, restores, and clustering inside a mostly stateless and idempotent reconciliation loop isn't the easiest. Even if you follow best practices by writing a variety of simple controllers, with each managing its own clearly-defined CR, the reconciliation logic can still be very error-prone and time-consuming to write. While frameworks like Operator SDK exist to help you with scaffolding your operator and libraries like Kubebuilder provide a set of incredibly useful controller libraries, it's still a lot of work to undertake.
K8s Is Just a Tool
At the end of the day, k8s is a single tool in the DevOps engineer's toolkit. These days, it's possible to host workloads in a variety of ways, using managed services (PaaS), k8s, VMs, or even running on a bare metal server. The tool that you choose depends on a variety of factors, including time, experience, performance requirements, ease of use, and cost.
While hosting a database on k8s might be a fit for your organization, it just as easily could create even more overhead and instability if not done carefully. Implementing the Day 2 features that I described above is time-consuming and costly to get right. Testing is incredibly important since you want to be absolutely sure that your (and your customers') precious data is kept safe and accessible when it's needed.
If you just need a reliable database to run your application on top of, then maybe all of the work required to run a database on k8s might be too much for you to undertake. But if your database has strong k8s support (most likely via an operator), or you are doing something unique (and at scale) with your storage layer, it might be worth it to look more into managing your stateful databases on k8s. Just be prepared for a large time investment and ensure that you have the requisite in-house knowledge (or support) so that you can be confident that you're performing your database automation activities correctly and safely.
We Provide consulting, implementation, and management services on DevOps, DevSecOps, Cloud, Automated Ops, Microservices, Infrastructure, and Security
Services offered by us: https://www.zippyops.com/services
Our Products: https://www.zippyops.com/products
Our Solutions: https://www.zippyops.com/solutions
For Demo, videos check out YouTube Playlist: https://www.youtube.com/watch?v=4FYvPooN_Tg&list=PLCJ3JpanNyCfXlHahZhYgJH9-rV6ouPro
If this seems interesting, please email us at [email protected] for a call.
Recent Comments
No comments
Leave a Comment
We will be happy to hear what you think about this post