Understanding Data Compaction in 3 Minutes

Think of your disks as a warehouse: The compaction mechanism is like a team of storekeepers who help put away the incoming data.
What is compaction in the database? Think of your disks as a warehouse: The compaction mechanism is like a team of storekeepers (with genius organizing skills like Marie Kondo) who help put away the incoming data.
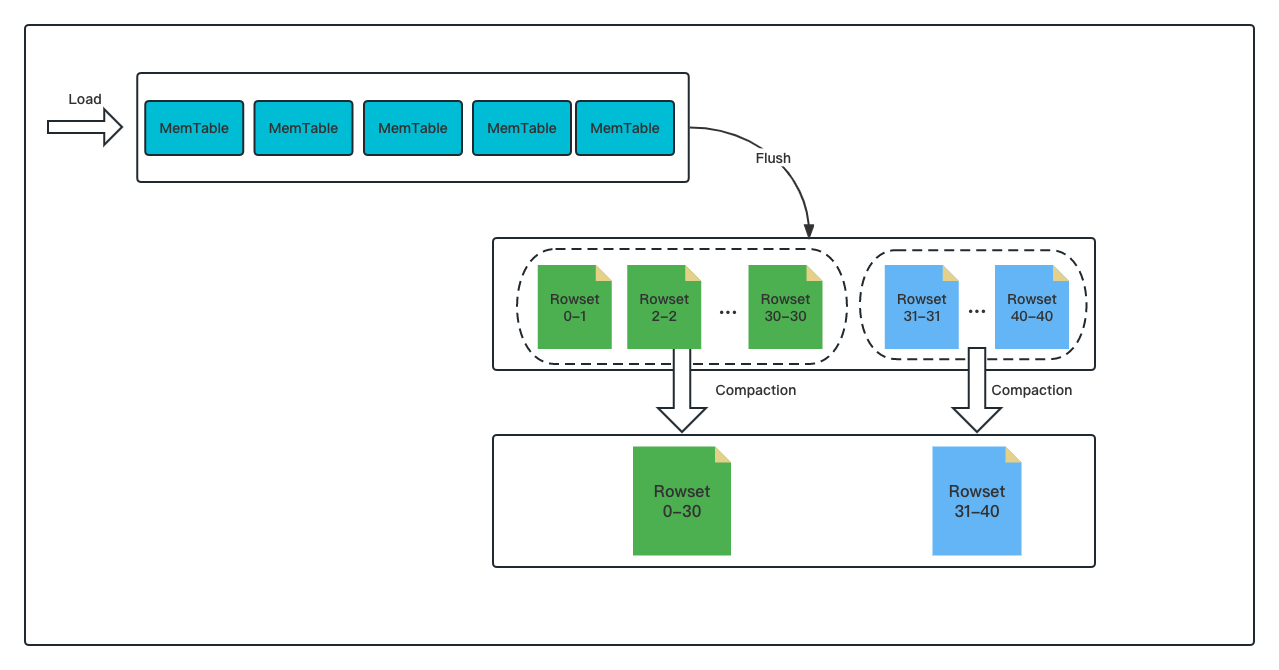
In particular, the data (which is the inflowing cargo in this metaphor) comes in on a "conveyor belt," which does not allow cutting in line. This is how the LSM-Tree (Log Structured-Merge Tree) works: In data storage, data is written into MemTables in an append-only manner, and then the MemTables are flushed to disks to form files. (These files go by different names in different databases. In my community, we call them Rowsets). Just like putting small boxes of cargo into a large container, compaction means merging multiple small rowset files into a big one, but it does much more than that. As I said, the compaction mechanism is an organizing magician:
- Although the items (data) in each box (rowset) are orderly arranged, the boxes themselves are not. Hence, one thing that the "storekeepers" do is to sort the boxes (rowsets) in a certain order so they can be quickly found once needed (quickening data reading).
- If an item needs to be discarded or replaced, since no line jump is allowed on the conveyor belt (append-only), you can only put a "note" (together with the substitution item) at the end of the queue on the belt to remind the "storekeepers," who will later perform replacing or discarding for you.
- If needed, the "storekeepers" are even kind enough to pre-process the cargo for you (pre-aggregating data to reduce computation burden during data reading).
As helpful as the "storekeepers" are, they can be troublemakers at times — that's why "team management" matters. For the compaction mechanism to work efficiently, you need wise planning and scheduling, or else you might need to deal with high memory and CPU usage, if not OOM in the backend or write error.
Specifically, efficient compaction is added up by quickly triggering compaction tasks, controllable memory and CPU overheads, and easy parameter adjustment from the engineer's side. That begs the question: How? In this post, I will show you our way, including how we trigger, execute, and fine-tune compaction for faster and less resource-hungry execution.
Trigger Strategies
The overall objective here is to trigger compaction tasks timely with the least resource consumption possible.
Active Trigger
The most intuitive way to ensure timely compaction is to scan for potential compaction tasks upon data ingestion. Every time a new data tablet version is generated, a compaction task is triggered immediately, so you will never have to worry about version buildup. But this only works for newly ingested data. This is called Cumulative Compaction, as opposed to Base Compaction, which is the compaction of existing data.
Passive Scan
Base compaction is triggered by a passive scan. The passive scan is a much heavier job than the active trigger because it scans all metadata in all data tablets in the node. After identifying all potential compaction tasks, the system starts compaction for the most urgent data tablet.
Tablet Dormancy
Frequent metadata scanning is a waste of CPU resources, so it is better to introduce dormancy: For tablets that have been producing no compaction tasks for a long, the system just stops looking at them for a while. If there is a sudden data write on a dormant tablet, that will trigger cumulative compaction, as mentioned above, so no worries, you won't miss anything.
The combination of these three strategies is an example of cost-effective planning.
Execution
Vertical Compaction for Columnar Storage
As columnar storage is the future for analytic databases, the execution of compaction should adapt to that. We call it vertical compaction. I illustrate this mechanism with the figure below:
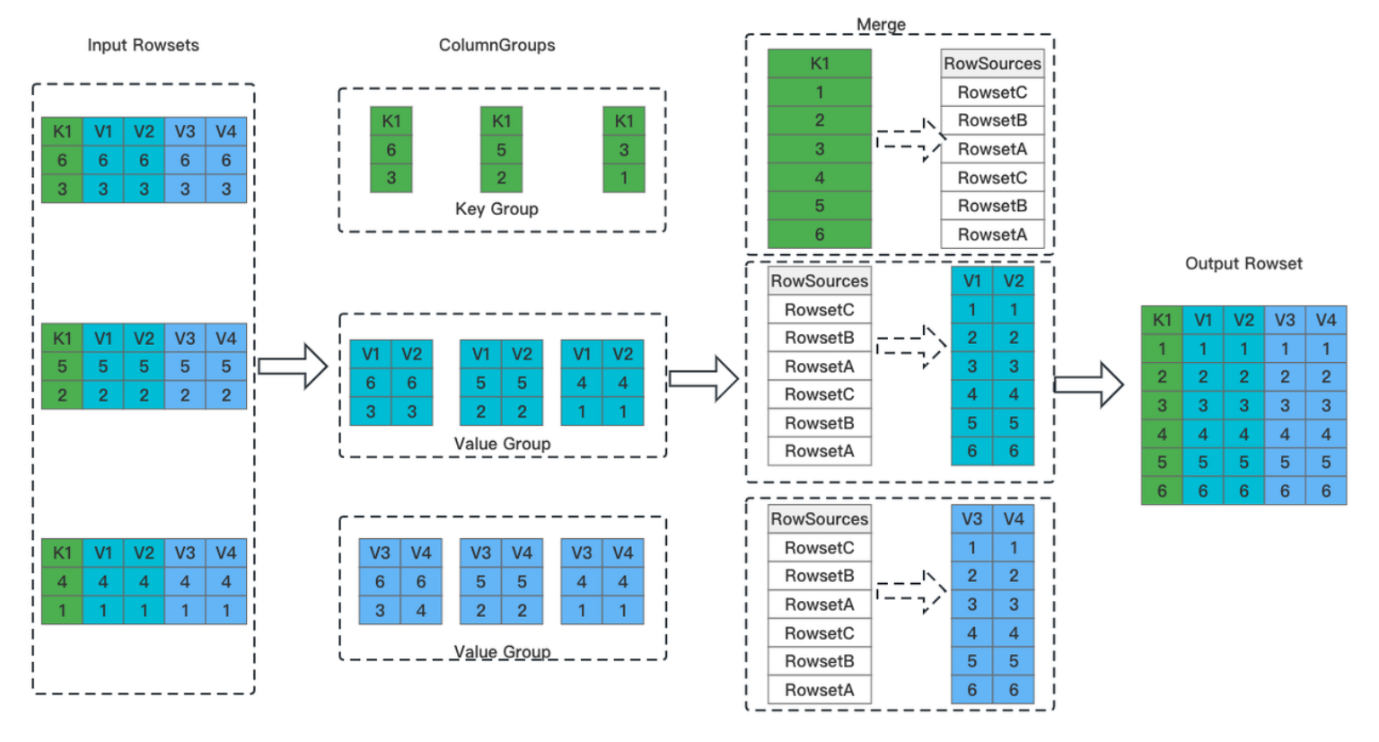
Hope all these tiny blocks and numbers don't make you dizzy. Actually, vertical compaction can be broken down into four simple steps:
1. Separate key columns and value columns. Split out all key columns from the input rowsets and put them into one group, and all value columns into N groups.
2. Merge the key columns. Heap sort is used in this step. The product here is a merged and ordered key column and a global sequence marker (RowSources).
3. Merge the value columns. The value columns are merged and organized based on the sequence in RowSources.
4. Write the data. All columns are assembled together and form one big rowset.
As a supporting technique for columnar storage, vertical compaction avoids the need to load all columns in every merging operation. That means it can vastly reduce memory usage compared to traditional row-oriented compaction.
Segment Compaction To Avoid "Jams"
As described in the beginning, in data ingestion, data will first be piled in the memory until it reaches a certain size and then flushed to disks and stored in the form of files. Therefore, if you have ingested one huge batch of data at a time, you will have a large number of newly generated files on the disks. That adds to the scanning burden during data reading and thus slows down data queries. (Imagine that suddenly you have to look into 50 boxes instead of 5 to find the item you need. That's overwhelming.) In some databases, such an explosion of files could even trigger a protection mechanism that suspends data ingestion.
Segment compaction is the way to avoid that. It allows you to compact data at the same time you ingest it so that the system can ingest a larger data size quickly without generating too many files.
This is a flow chart that explains how segment compaction works:
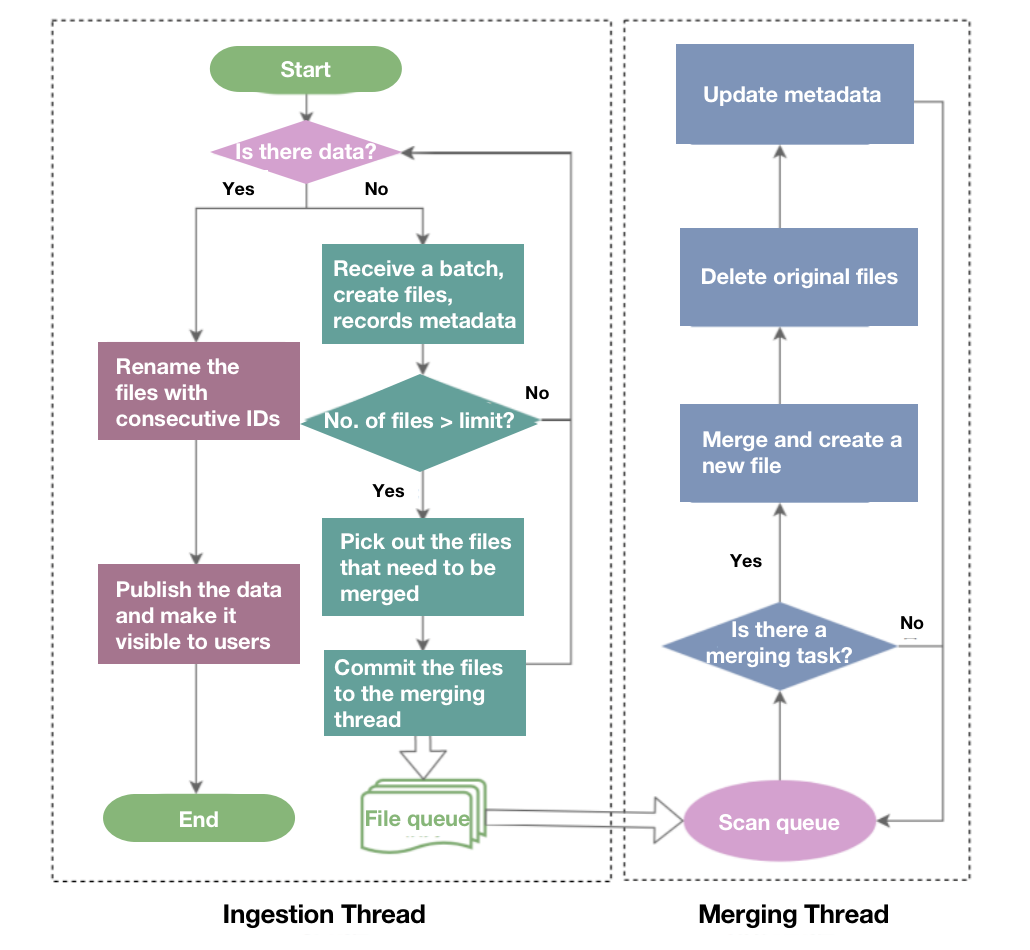
Segment compaction will be triggered once the number of newly generated files exceeds a certain limit (let's say 10). It is executed asynchronously by a specialized merging thread. Every ten files will be merged into one, and the original ten files will be deleted. Segment compaction does not prolong the data ingestion process much but can largely accelerate data queries.
Ordered Data Compaction
Time series data analysis is an increasingly common analytic scenario.
Time series data is "born orderly." It is already arranged chronologically, it is written at a regular pace, and every batch of it is of similar size. It is like the least-worried-about child in the family. Correspondingly, we have a tailored compaction method for it: ordered data compaction.
Ordered data compaction is even simpler:
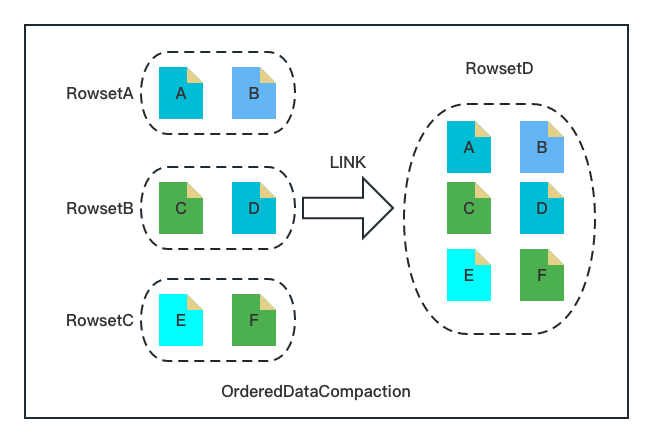
- Upload: Jot down the Min/Max Keys of the input rowset files.
- Check: Check if the rowset files are organized correctly based on the Min/Max Keys and the file size.
- Merge: Hard link the input rowsets to the new rowset and create metadata for the new rowset (including the number of rows, file size, Min/Max Key, etc.)
See? It is a super neat and lightweight workload involving only file linking and metadata creation. Statistically, it just takes milliseconds to compact huge amounts of time series data but consumes nearly zero memory.
So far, these are strategic and algorithmic optimizations for compaction, implemented by Apache Doris 2.0.0, a unified analytic database. Apart from these, we, as developers for the open-source project, have fine-tuned it from an engineering perspective.
Engineering Optimizations
Zero-Copy
In the backend nodes of Apache Doris, data goes through a few layers: Tablet -> Rowset -> Segment -> Column -> Page. The compaction process involves data transferring that consumes a lot of CPU resources. So we designed zero-copy compaction logic, which is realized by a data structure named BlockView. This brings another 5% increase in compaction efficiency.
Load-on-Demand
In most cases, the rowsets are not 100% orderless, so we can take advantage of such partial orderliness. For a group of ordered rowsets, Apache Doris only loads the first one and then starts merging. As the merging goes on, it gradually loads the rowset files it needs. This is how it decreases memory usage.
Idle Schedule
According to our experience, base compaction tasks are often resource-intensive and time-consuming, so they can easily stand in the way of data queries. Doris 2.0.0 enables Idle Schedule, deprioritizing those base compaction tasks with huge data, long execution, and low compaction rate.
Parameter Optimizations
Every data engineer has somehow been harassed by complicated parameters and configurations. To protect our users from this nightmare, we have provided a streamlined set of parameters with the best-performing default configurations in the general environment.
Conclusion
This is how we keep our "storekeepers" working efficiently and cost-effectively. If you wonder how these strategies and optimization work in real practice, we tested Apache Doris with ClickBench. It reaches a compaction speed of 300,000 row/s; in high-concurrency scenarios, it maintains a stable compaction score of around 50. Also, we are planning to implement auto-tuning and increase observability for the compaction mechanism.
We Provide consulting, implementation, and management services on DevOps, DevSecOps, DataOps, Cloud, Automated Ops, Microservices, Infrastructure, and Security
Services offered by us: https://www.zippyops.com/services
Our Products: https://www.zippyops.com/products
Our Solutions: https://www.zippyops.com/solutions
For Demo, videos check out YouTube Playlist: https://www.youtube.com/watch?v=4FYvPooN_Tg&list=PLCJ3JpanNyCfXlHahZhYgJH9-rV6ouPro
If this seems interesting, please email us at [email protected] for a call.
Relevant Blogs:
Ethical AI and Responsible Data Science: What Can Developers Do?
Managing Application Logs and Metrics With Elasticsearch and Kibana
The Effect of Data Storage Strategy on PostgreSQL Performance
Recent Comments
No comments
Leave a Comment
We will be happy to hear what you think about this post