From Hadoop to Cloud: Why and How to Decouple Storage and Compute in Big Data Platforms

In this article, learn the importance and feasibility of storage-compute decoupling and explore available market solutions.
The advent of Apache Hadoop Distributed File System (HDFS) revolutionized the storage, processing, and analysis of data for enterprises, accelerating the growth of big data and bringing about transformative changes to the industry.
Initially, Hadoop integrated storage and compute, but the emergence of cloud computing led to a separation of these components. Object storage emerged as an alternative to HDFS but had limitations. To complement these limitations, JuiceFS, an open-source, high-performance distributed file system, offers cost-effective solutions for data-intensive scenarios like computation, analysis, and training. The decision to adopt storage-compute separation depends on factors like scalability, performance, cost, and compatibility.
In this article, we’ll review the Hadoop architecture, discuss the importance and feasibility of storage-compute decoupling, and explore available market solutions, highlighting their respective pros and cons. Our aim is to provide insights and inspiration to enterprises undergoing storage-compute separation architecture transformation.
Hadoop Architecture Design Features
Hadoop as an All-In-One Framework
In 2006, Hadoop was released as an all-in-one framework consisting of three components:
- MapReduce for computation
- YARN for resource scheduling
- HDFS for distributed file storage
Core components of Hadoop

Diverse Computation Components
Among these three components, the computation layer has seen rapid development. Initially, there was only MapReduce, but the industry soon witnessed the emergence of various frameworks like Tez and Spark for computation, Hive for data warehousing, and query engines like Presto and Impala. In conjunction with these components, there are numerous data transfer tools like Sqoop.
Diverse computation components

HDFS Dominated the Storage System
Over approximately ten years, HDFS, the distributed file system, had remained the dominant storage system. It was the default choice for nearly all computation components. All the above-mentioned components within the big data ecosystem were designed for the HDFS API. Some components deeply leverage the specific capabilities of HDFS. For example:
- HBase utilizes the low-latency writing capabilities of HDFS for their write-ahead logs.
- MapReduce and Spark provided data locality features.
The design choices of these big data components, based on the HDFS API, brought potential challenges for deploying data platforms to the cloud.
Storage-Compute Coupled Architecture
The following diagram shows part of a simplified HDFS
architecture, which couples compute with storage.
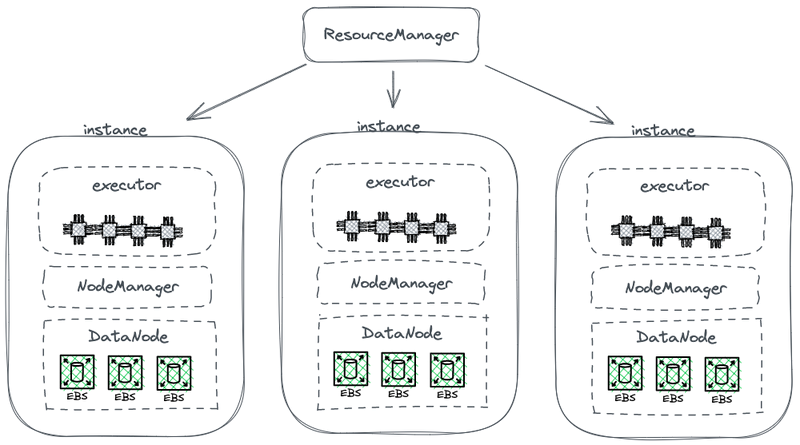
Hadoop storage-compute coupled architecture
In this diagram, each node serves as an HDFS DataNode for storing data. Additionally, YARN deploys a Node Manager process on each node. This enables YARN to recognize the node as part of its managed resources for computing tasks. This architecture allows storage and compute to coexist on the same machine, and data can be read from the disk during computation.
Why Hadoop Coupled Storage and Compute
Hadoop coupled storage and compute due to the limitations of network communication and hardware during its design phase.
In 2006, cloud computing was still in its nascent stage, and Amazon had just released its first service. In data centers, the prevailing network cards were primarily operating at 100 Mbps. Data disks used for big data workloads achieved a throughput of approximately 50 MB/s, equivalent to 400 Mbps in terms of network bandwidth.
Considering a node with eight disks running at maximum capacity, several gigabits per second of network bandwidth were needed for efficient data transmission. Unfortunately, the network cards' maximum capacity was limited to 1 Gbps. As a result, the network bandwidth per node was insufficient to fully utilize the capabilities of all disks within the node. Consequently, if computing tasks were at one end of the network and the data resided on data nodes at the other end, the network bandwidth was a significant bottleneck.
Why Storage-Compute Decoupling Is Necessary
From 2006 to around 2016, enterprises faced the following issues:
- The demand for computing power and storage in applications was imbalanced, and their growth rates differed. While enterprise data grew rapidly, the need for computing power did not grow that fast. These tasks, developed by humans, did not multiply exponentially in a short period. However, the data generated from these tasks accumulated rapidly, possibly in an exponential manner. Additionally, some data might not be immediately useful to the enterprise, but it would be valuable in the future. Therefore, enterprises stored the data comprehensively to explore its potential value.
- During scaling, enterprises had to expand both compute and storage simultaneously, which often led to wasted computing resources. The hardware topology of storage-compute coupled architecture affected capacity expansion. When storage capacity fell short, we needed to not only add machines but also upgrade CPUs and memory since data nodes in the coupled architecture were responsible for computation. Therefore, machines were typically equipped with a well-balanced computing power and storage configuration, providing sufficient storage capacity along with comparable computing power. However, the actual demand for computing power did not increase as anticipated. As a result, the expanded computing power caused a big waste for enterprises.
- Balancing computing and storage and selecting suitable machines became challenging. The entire cluster's resource utilization in terms of storage and I/O could be highly imbalanced, and this imbalance worsened as the cluster grew larger. Moreover, procuring appropriate machines was difficult, as the machines had to strike a balance between computing and storage requirements.
- Because data could be unevenly distributed, it was difficult to effectively schedule computing tasks on the instances where the data resided. The data locality scheduling strategy may not effectively address real-world scenarios due to the possibility of imbalanced data distribution. For example, certain nodes might become local hotspots, requiring more computing power. Consequently, even if tasks on the big data platform were scheduled to these hotspot nodes, I/O performance might still become a limiting factor.
Why Decoupling Storage and Compute Is Feasible
The feasibility of separating storage and compute was made possible by advancements in hardware and software between 2006 and 2016. These advancements include:
Network Cards
The adoption of 10 Gb network cards has become widespread, with increasing availability of higher capacities such as 20 Gb, 40 Gb, and even 50 Gb in data centers and cloud environments. In AI scenarios, network cards with a capacity of 100 GB are also used. This represents a significant increase in network bandwidth by over 100 times.
Disks
Many enterprises still rely on disk-based solutions for storage in large data clusters. The throughput of disks has doubled, increasing from 50 MB/s to 100 MB/s. An instance equipped with a 10 GB network card can support a peak throughput of about 12 disks. This is sufficient for most enterprises, and thus, the network transmission is no longer a bottleneck.
Software
The use of efficient compression algorithms such as Snappy, LZ4, and Zstandard and columnar storage formats like Avro, Parquet, and Orc has further alleviated I/O pressure. The bottleneck in big data processing has shifted from I/O to CPU performance.
How To Implement Storage-Compute Separation
Initial Attempt: Independent Deployment of HDFS to the Cloud
Independent Deployment of HDFS
Since 2013, there have been attempts within the industry to separate storage and compute. The initial approach is quite straightforward, involving the independent deployment of HDFS without integrating it with the computing workers. This solution did not introduce any new components to the Hadoop ecosystem.
As shown in the diagram below, the NodeManager was no longer deployed on DataNodes. This indicated that computing tasks were no longer sent to DataNodes. Storage became a separate cluster, and the data required for computations was transmitted over the network, supported by end-to-end 10 Gb network cards. (Note that the network transmission lines are not marked in the diagram.)
Separating storage from compute
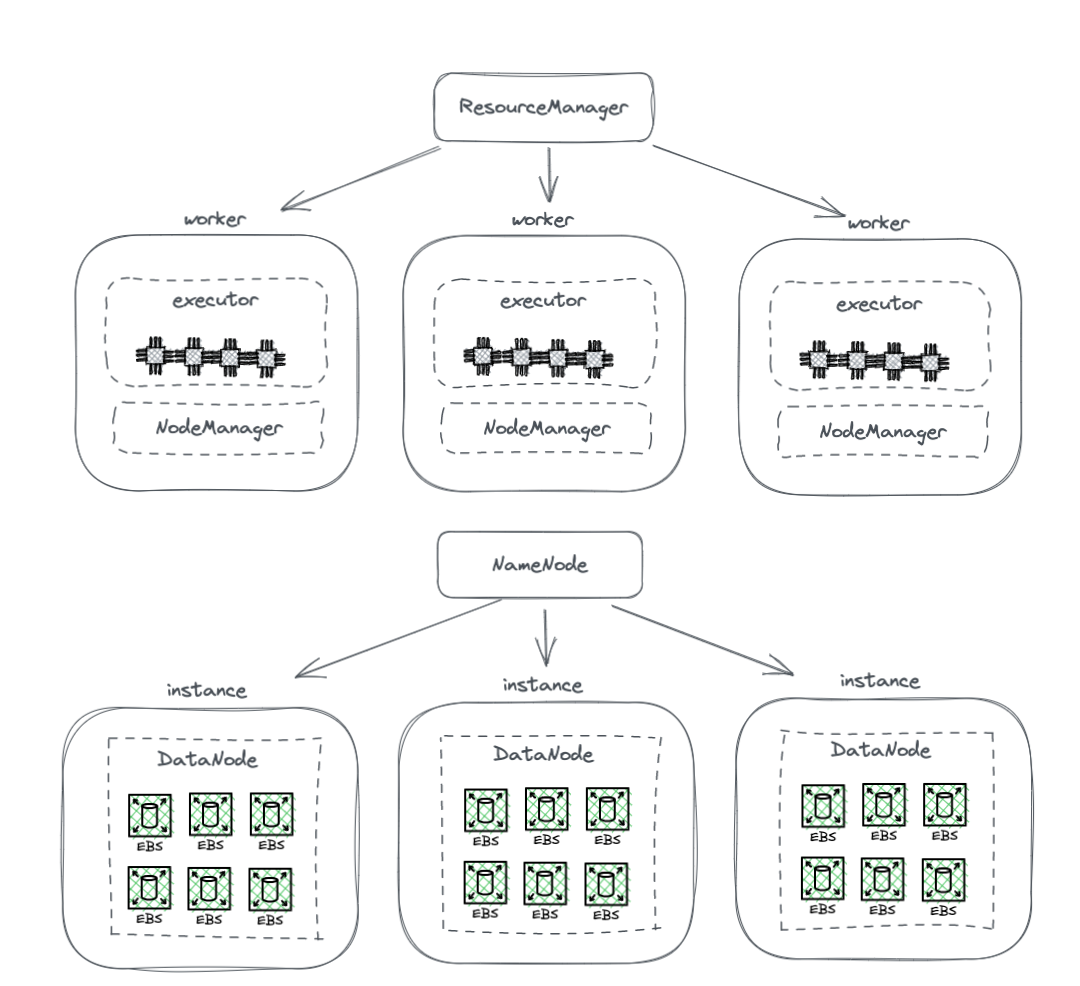
Although this solution abandoned data locality, the most ingenious design of HDFS, the enhanced speed of network communication significantly facilitated cluster configuration.
Challenges of Deploying HDFS to the Cloud
Deploying HDFS to the cloud faces the following issues:
- The HDFS multi-replica mechanism can increase the cost of enterprises on the cloud: In the past, enterprises used bare disks to build an HDFS system in their data centers. To mitigate the disk damage risk, HDFS implemented a multi-replica mechanism to ensure data safety and availability. However, when migrating data to the cloud, cloud providers offer cloud disks that are already protected by the multi-replica mechanism. Consequently, enterprises need to replicate data three times within the cloud, resulting in a significant increase in costs.
- Limited options for deploying on bare disks: While cloud providers offer some machine types with bare disks, the available options are limited. For example, out of 100 virtual machine types available in the cloud, only 5-10 machine types support bare disks. This limited selection may not meet the specific requirements of enterprise clusters.
- Inability to leverage the unique advantages of the cloud: Deploying HDFS to the cloud requires manual machine creation, deployment, maintenance, monitoring, and operations without the convenience of elastic scaling and the pay-as-you-go model. These are the key advantages of cloud computing. Therefore, deploying HDFS to the cloud while achieving storage-compute separation is not easy.
HDFS Limitations
HDFS itself has these limitations:
- NameNodes have limited scalability: The NameNodes in HDFS can only scale vertically and cannot scale distributedly. This limitation imposes a constraint on the number of files that can be managed within a single HDFS cluster.
- Storing more than 500 million files brings high operations costs: According to our experience, it is generally easy to operate and maintain HDFS with less than 300 million files. When the number of files surpasses 500 million, the HDFS Federation mechanism needs to be implemented. However, this introduces high operations and management costs.
- High resource usage and heavy load on the NameNode impact HDFS cluster availability: When a NameNode takes up too many resources with a high load, full garbage collection (GC) may be triggered. This affects the availability of the entire HDFS cluster. The system storage may experience downtime, rendering it unable to read data, and there is no way to intervene in the GC process. The duration of the system freeze cannot be determined. This has been a persistent issue in high-load HDFS clusters.
Public Cloud + Object Storage
With the advancement of cloud computing, enterprises now have the option of using object storage as an alternative to HDFS. Object storage is specifically designed for storing large-scale unstructured data, offering an architecture for easy data upload and download. It provides highly scalable storage capacity, ensuring cost-effectiveness.
Benefits of Object Storage as an HDFS Replacement
Object storage has gained traction, starting with AWS and subsequently being adopted by other cloud providers as a replacement for HDFS. The following advantages are notable:
- Service-oriented and out-of-the-box: Object storage requires no deployment, monitoring, or maintenance tasks, providing a convenient and user-friendly experience.
- Elastic scaling and pay-as-you-go: Enterprises pay for object storage based on their actual usage, eliminating the need for capacity planning. They can create an object storage bucket and store as much data as necessary without concerns about storage capacity limitations.
Drawbacks of Object Storage
However, when using object storage to support complex data systems like Hadoop, the following challenges arise:
Drawback #1: Poor Performance of File Listing
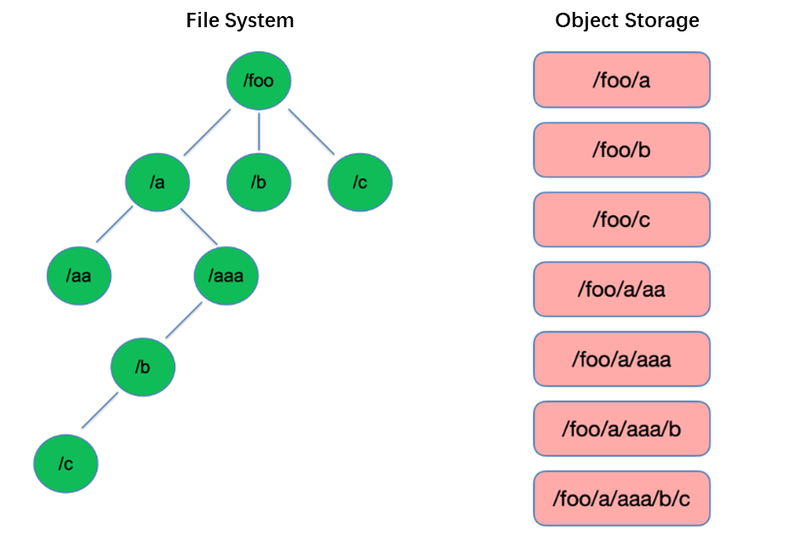
Listing is one of the most basic operations in the file system. It is lightweight and fast in tree-like structures such as HDFS.
In contrast, object storage adopts a flat structure and requires indexing with keys (unique identifiers) for storing and retrieving thousands or even billions of objects. As a result, when performing a List operation, object storage can only search within this index, leading to significantly inferior performance compared to tree-like structures.
Tree-like structure vs. flat structure
Drawback #2: Lack of Atomic Rename Capability, Affecting Task Performance and Stability
In extract, transform, load (ETL) computing models, each subtask writes its results to a temporary directory. When the entire task is completed, the temporary directory can be renamed to the final directory name.
These Rename operations are atomic and fast in file systems like HDFS, and they guarantee transactions. However, because object storage does not have a native directory structure, handling a Rename operation is a simulated process that involves a substantial amount of internal data copying. This process can be time-consuming and does not provide transactional guarantees.
When users employ object storage, they commonly use the path format from traditional file systems as the key for objects, such as "/order/2-22/8/10/detail." During a Rename operation, it becomes necessary to search for all objects whose keys contain the directory name and copy all objects using the new directory name as the key. This process involves data copying, leading to significantly lower performance compared to file systems, potentially slower by one or two orders of magnitude.
Additionally, due to the absence of transactional guarantees, there is a risk of failure during the process, resulting in incorrect data. These seemingly minor differences have implications for the performance and stability of the entire task pipeline.
Drawback #3: The Eventual Consistency Mechanism Affects Data Correctness and Task Stability
For example, when multiple clients concurrently create files under a path, the file list obtained through the List API may not immediately include all the created files. It takes time for the object storage's internal systems to achieve data consistency. This access pattern is commonly used in ETL data processing, and eventual consistency can impact data correctness and task stability.
To address the issue of object storage's inability to maintain strong data consistency, AWS released a product called EMRFS. Its approach is to employ an additional DynamoDB database. For example, when Spark writes a file, it also simultaneously writes a copy of the file listing to DynamoDB. A mechanism is then established to continuously call the List API of the object storage and compare the obtained results with the stored results in the database until they are the same, at which point the results are returned. However, the stability of this mechanism is not good enough as it can be influenced by the load on the region where the object storage is located, resulting in variable performance. Thus, it is not an ideal solution.
Drawback #4: Limited Compatibility With Hadoop Components
HDFS was the primary storage choice in the early stages of the Hadoop ecosystem, and various components were developed based on the HDFS API. The introduction of object storage has led to changes in the data storage structure and APIs.
Cloud providers need to modify connectors between components and cloud object storage, as well as patch upper-layer components to ensure compatibility. This task places a significant workload on public cloud providers.
Consequently, the number of supported computing components in big data platforms offered by public cloud providers is limited, typically including only a few versions of Spark, Hive, and Presto. This limitation poses challenges for migrating big data platforms to the cloud or for users with specific requirements for their own distribution and components.
To leverage the powerful performance of object storage while preserving the reliability of file systems, enterprises can use object storage + JuiceFS.
Object Storage + JuiceFS
When users want to perform complex data computation, analysis, and training on object storage, object storage alone may not adequately meet enterprise requirements. This is a key motivation behind Juicedata's development of JuiceFS, which aims to complement the limitations of object storage.
JuiceFS is an open-source, high-performance distributed file system designed for the cloud. Together with object storage, JuiceFS provides cost-effective solutions for data-intensive scenarios such as computation, analysis, and training.
How JuiceFS + Object Storage Works
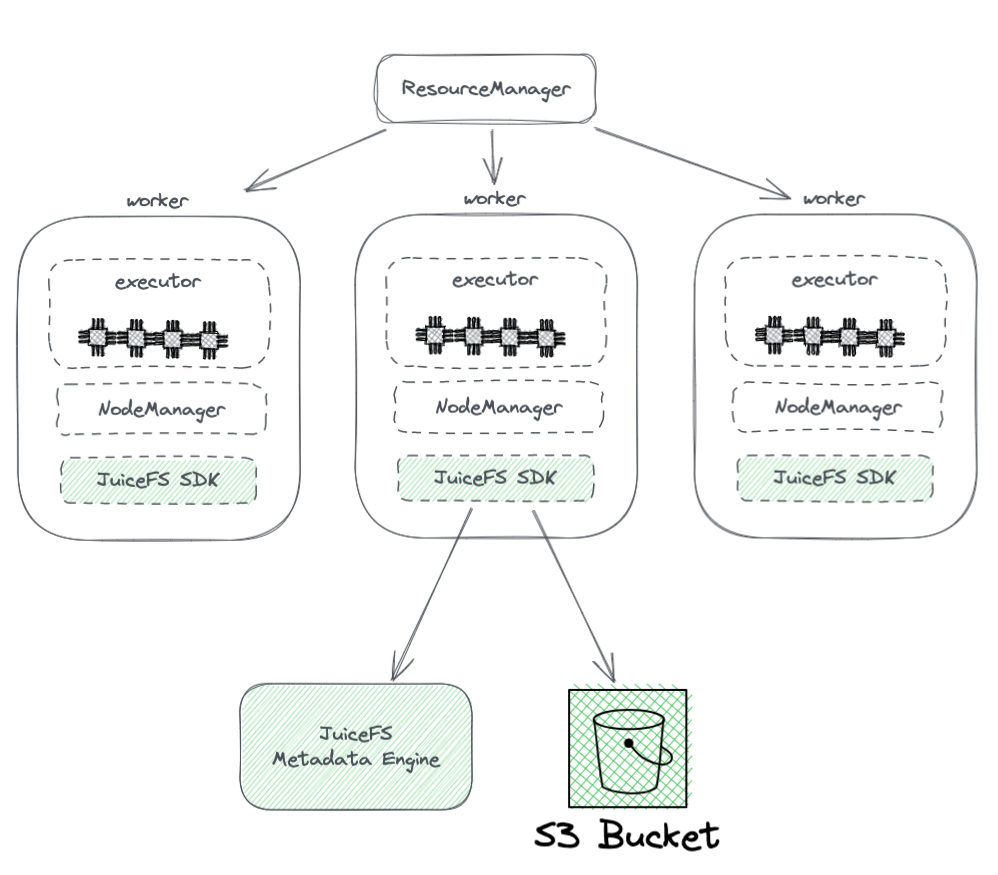
The diagram below shows the deployment of JuiceFS within a Hadoop cluster.
JuiceFS deployment in the Hadoop cluster
From the diagram, we can see the following:
- All the worker nodes managed by YARN carry a JuiceFS Hadoop SDK, which can guarantee the full compatibility with HDFS.
- The SDK accesses two components:
o JuiceFS Metadata Engine: The metadata engine serves as the counterpart to HDFS' NameNode. It stores the metadata information of the entire file system, including directory counts, file names, permissions, and timestamps, and resolves scalability and GC challenges faced by HDFS' NameNode.
o S3 Bucket: The data is stored within the S3 bucket, which can be seen as analogous to HDFS's DataNode. It can be used as a large number of disks, managing data storage and replication tasks.
· JuiceFS consists of three components:
- JuiceFS Hadoop SDK
- Metadata Engine
- S3 Bucket
Advantages of Juicefs Over Direct Use of Object Storage
JuiceFS offers several advantages compared to the direct use of object storage:
- Full compatibility with HDFS: This is achieved by JuiceFS' initial design to fully support POSIX. The POSIX API has greater coverage and complexity than HDFS.
- Ability to use with existing HDFS and object storage: Thanks to the design of the Hadoop system, JuiceFS can be used alongside existing HDFS and object storage systems without the need for a complete replacement. In a Hadoop cluster, multiple file systems can be configured, allowing JuiceFS and HDFS to coexist and collaborate. This architecture eliminates the need for a full replacement of existing HDFS clusters, which would involve significant effort and risks. Users can gradually integrate JuiceFS based on their application needs and cluster situations.
- Powerful metadata performance: JuiceFS separates the metadata engine from the S3 and no longer relies on the S3 metadata performance. This ensures optimal metadata performance. When using JuiceFS, interactions with the underlying object storage are simplified to basic operations such as Get, Put, and Delete. This architecture overcomes the performance limitations of object storage metadata and eliminates issues related to eventual consistency.
- Support for atomic Rename: JuiceFS supports atomic Rename operations due to its independent metadata engine. Cache improves access performance of hot data and provides the data locality feature: With cache, hot data no longer needs to be retrieved from object storage through the network every time. Moreover, JuiceFS implements the HDFS-specific data locality API, so that all upper-layer components that support data locality can regain the awareness of data affinity. This allows YARN to prioritize scheduling tasks on nodes where caching has been established, resulting in overall performance comparable to storage-compute coupled HDFS.
- JuiceFS is compatible with POSIX, making it easy to integrate with machine learning and AI-related applications.
Conclusion
With the evolution of enterprise requirements and advancements in technologies, the architecture of storage and compute has undergone changes, transitioning from coupling to separation.
There are diverse approaches to achieving storage and compute separation, each with its own advantages and disadvantages. These range from deploying HDFS to the cloud to utilizing public cloud solutions that are compatible with Hadoop and even adopting solutions like object storage + JuiceFS, which are suitable for complex big data computation and storage in the cloud.
For enterprises, there is no silver bullet, and the key lies in selecting the architecture based on their specific needs. However, regardless of the choice, simplicity is always a safe bet.
We Provide consulting, implementation, and management services on DevOps, DevSecOps, DataOps, Cloud, Automated Ops, Microservices, Infrastructure, and Security
Services offered by us: https://www.zippyops.com/services
Our Products: https://www.zippyops.com/products
Our Solutions: https://www.zippyops.com/solutions
For Demo, videos check out YouTube Playlist: https://www.youtube.com/watch?v=4FYvPooN_Tg&list=PLCJ3JpanNyCfXlHahZhYgJH9-rV6ouPro
If this seems interesting, please email us at [email protected] for a call.
Recent Comments
No comments
Leave a Comment
We will be happy to hear what you think about this post