GitHub Shared Responsibility Model and Source Code Protection

Find out what obligations GitHub users have within the Shared Responsibility model, and learn which measures to take to protect your data.
It is human nature to start thinking about a problem after it has already occurred — we don’t like to learn from somebody’s mistakes, though it is a good idea. But what if we consider a situation when the GitHub online code repository stops working for a while? Well, such things happen sometimes, though GitHub is a highly reliable vendor with numerous compliance certificates and standards, like ISO/IEC 27001:2013, GDPR, FedRAM LI-SaaS ATO, SOC 1, and SOC 2, and it is a Trusted Cloud Provider with CSA.
Still, starting to use GitHub as a git repository service, it is great to know from the beginning what your responsibilities, as a user, are and what GitHub can guarantee. So, let’s figure out what both parties are responsible for and how it works because usually, customers don’t even think about this mentioned Shared Responsibility Model.
What the Shared Responsibility Model Is
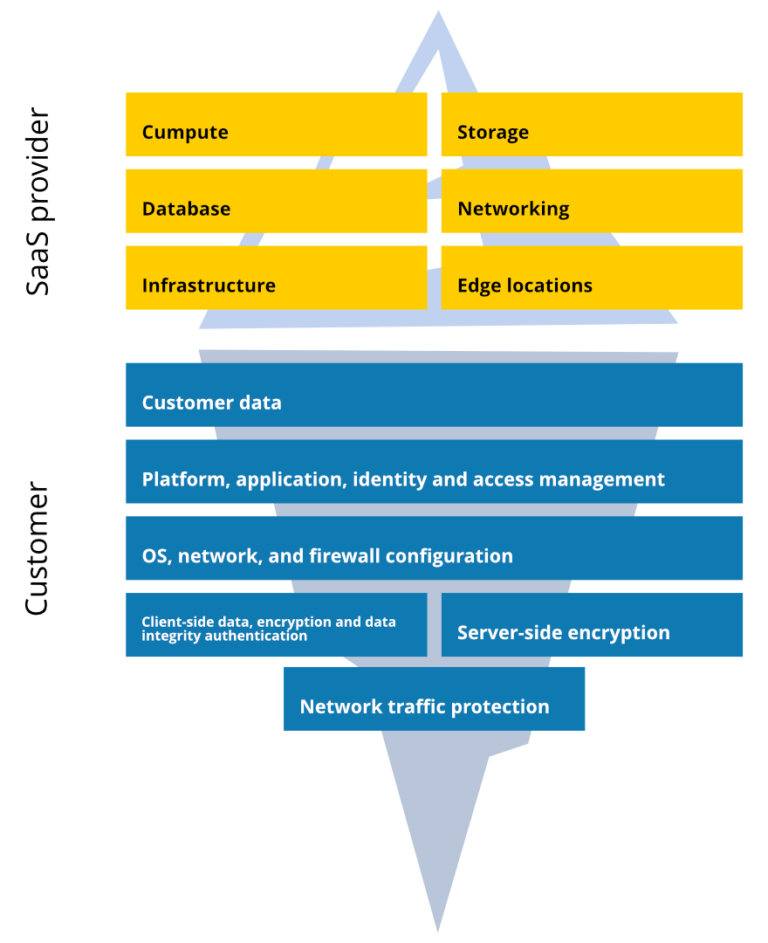
To understand how the Shared Responsibility Model really works, we should, first, define what it is. And to see what is the GitHub Shared Responsibility Model, we should know that every Software-as-a-Service (SaaS) provider operates due to those rules so GitHub, being a SaaS provider, has the same bunch of responsibilities. So, it is essential that SaaS providers work according to data security measures, otherwise, nobody would use the service they provide. But what does this security policy include?
The following model defines the security behavior and duties that should be done by a service provider and the ones that belong to the organization as a customer. Thus, it takes care of operating systems, network controls, applications, physical hosts, network and data centers, and partly for the identity and directory infrastructure. So, to explain it simply, the Shared Responsibility Model includes the protection of the entire environment, but not the separate account domain.
Is the Shared Responsibility Model a Hidden Set of Regulations or a Reality?
So, you, as a customer, should take care of your own data, manage the information security, access to the data, control of the apps you install, and trust. Besides all the aforementioned, it is the customer who should meet policy and compliance requirements. In a situation when some natural catastrophe happens and influences its servers, or a bad actor manages to breach the GitHub system and corrupt the entire database, the Shared Responsibility Model works, but what if some troubles happen to the data of a private GitHub account? What to say if it is a company with a number of developers working on the same code to be launched at a definite time? In a case like that, this model takes off the responsibility of the provider, as it is the customer’s responsibility to take care of his data.
According to the Shared Responsibility Model, GitHub and the user share the following aspects, as infrastructure, storage, compliance, retention, and restore.
Infrastructure
When we speak about infrastructure, we should mention that being a storage provider, GitHub is responsible for the security of the cloud, so to say the entire system and its environment. On the other hand, you, as a customer, are responsible for the security in the cloud — your data protection in your own GitHub environment.
Storage
The next point is storage. GitHub stores and encrypts your data-at-rest; meanwhile, you should take care of the storage capacity and multiple copies that you want to make.
Compliance
As we have already mentioned, GitHub is a proven vendor with an excellent list of compliance. Still, it is a customer’s obligation to check which legal and security terms they are compliant with.
Retention
GitHub provides its customers with limited retention. Thus, by default, public repositories can be retained for up to 90 days while owners of private repositories have the possibility to settle retention periods up to 400 days. It means that your deleted data (even accidentally) are possible to access and restore from a maximum of 90 or 400 days prior. If you need to make sure and keep copies for, i.e., 5 years due to your legal, internal, or compliance regulations, it is good to have a possibility of long-term retention or even keeping backups infinitely. In the event of failure, once your data is gone, you should be able to restore the copy from any point in time, even the one from 5 years ago to eliminate the risk of costly legal penalties and data loss.
Restore
Another thing is restore. If something happens to the entire GitHub environment, they will restore all the data, but if there is a problem with your own repository data, for example, accidental or intentional deletion, then it is your responsibility.
To sum up, it’s essential to mention here that GitHub is just a data processor, while the customer is a data owner. Thus, everything that determines the way and the purpose — the data is processed — is on the shoulders of the customer, and a data processor is a service that processes all that data when and if the data owner permits it.
What to Keep in Mind About Source Code Protection
Though GitHub highly values customers’ data and takes all the necessary measures to protect personal information from alterations, destructions, and unauthorized access, there are always some risks that can be found. So, looking closer at the responsibilities GitHub shares with its customers, we can define the so-called “limitations” the customers may face with their data security.
A Few Words About GitHub Backup
Usually, SaaS services provide basic backup plans, which may include snapshots. But, snapshots cannot be a reliable backup as it is just a state of the system at some definite time. Moreover, if a company decides to back up itself manually (let’s say with scripts), it will quickly understand that it can’t meet the company’s needs as it is time-consuming and error-prone. What is more, keeping and deleting multiple copies is going to be a tiring customer’s daily routine.
Here it is worth remembering about the 3-2-1 backup rule. Under this rule, it’s better to have three copies of your data in two different locations including one outside the company.
Encryption and Code Security
Another issue is encryption. GitHub states that all the git repository data is encrypted at rest and they have a high level of physical and network security. However, if the user decides to transfer his data to another cloud, it can be corrupted during transmission. Actually, there are a lot of threats that can happen to an account and its data, e.g., malware, bad actors, accidental/intentional deletion, and so on. So, there is no 100% secure method to protect the data. On the other hand, when your data is encrypted in-flight, usually it is a solution that backup companies offer, you can be definitely sure of your source code protection.
Is It Possible to Reduce the Customer’s Responsibility?
As we have already mentioned, according to “the shared responsibility model,” it is the user’s responsibility to think about their data to be accessible, available, protected, and recoverable at every moment, from any point-in-time to make sure no disaster can cause data loss, downtime, and financial losses. So, what are the options?
Deploying a Third-Party Backup Solution
Nowadays, developers share a lot of information on how to protect your git repository and there is a lot of information about snapshots, cloning the code, or even scripts to back up the repository and increase the code security. Though they do not always mention that it can work pretty well when we speak about personal use, not a company that relies on that so-called “backup.” That is why even GitHub suggests the option of a third-party backup solution. In a situation like that a backup and recovery company can share this responsibility with you. What does it mean? Let’s see step by step.
We have already said that in accordance with its infrastructure, GitHub takes care of the security of the cloud as it is, and for a customer, there is an obligation to think about his git repository environment. If we add a third-party backup solution, then it will share or even take this responsibility from you, as it provides automatic backup and data protection, and can perform the backup under the 3-2-1 rule.
Professional GitHub Backup Comes With Many Pros
A professional backup solution can help to reduce the customer’s responsibility for the storage, as it will not only use at-rest encryption but also in-flight encryption when transferring your data to any external storage. Moreover, you can optimize your storage usage with such features as compression and deduplication.
It is difficult to restore the data if there is no backup software in place. If a third-party solution appears in this acquisition, you will be able to have point-in-time recovery and disaster recovery features from any point-in-time, and it is you who chooses the retention type, whether it is GFS, FIFO, or forever incremental.
Let’s be honest — it is difficult for a business to stay compliant. So, when a customer decides to turn to a third-party backup and recovery company, it helps to meet all the mentioned compliance requirements to guard your data, including encryption, integrity, data restore, and disaster recovery.
When it comes to retention, isn’t it great to have an opportunity to have access to the code that you wrote 5 years ago, and now it is time to update it, even when it was deleted from GitHub? With backup turned on, it is possible. Well, even if your code is deleted from the GitHub repository because you wanted to overcome storage limits, you still will be able to restore it from the chosen copy and storage anytime you need it.
|
Area of responsibility |
GitHub’s responsibility share |
User’s responsibility share |
Third-party backup tool's responsibility share |
|
Infrastructure |
Uptime of GitHub service |
Access and control of the data in the GitHub repository |
Automatic backup and data protection, the implementation of the 3-2-1 rule |
|
Storage |
GitHub Cloud storage, at-rest encryption |
Keeping multiple copies |
On-premise, public/private cloud/hybrid- store your data anywhere you want |
|
Compliance |
SOC 1, SOC 2,ISO/IEC 20071, GDPR, FedRAM LI-SaaS ATO (data processor) |
Meeting legal compliance, local compliance, and industry regulations (data owner) |
Encryption, integrity, data restore, disaster recovery – we help you meet all your compliance requirements (data guard) |
|
Retention |
Basic retention (up to 90-days in the pubic repository, up to 400 days in the private repository) |
Long-term retention |
Flexible or unlimited, enterprise-grade data retention (and advanced retention schemes – Basic, GFS) as well as granular & point-in-time recovery options |
|
Restore |
Restore the entire platform only |
Own-written scripts, snapshots, clones |
Point-in-time restore of repositories and metadata, Cross-over recovery (and easy migration between platforms), Disaster Recovery Technologies, Restore to your local device. |
Summary
To sum up, we can say that the Shared Responsibility Model works well when you know your duties. It can help to reduce your stress, as you know what is on your shoulders. Moreover, you can share your obligations with other solutions and save your developers’ time so that they can peacefully work on the code for the sake of your company.
We Provide consulting, implementation, and management services on DevOps, DevSecOps, DataOps, Cloud, Automated Ops, Microservices, Infrastructure, and Security
Services offered by us: https://www.zippyops.com/services
Our Products: https://www.zippyops.com/products
Our Solutions: https://www.zippyops.com/solutions
For Demo, videos check out YouTube Playlist: https://www.youtube.com/watch?v=4FYvPooN_Tg&list=PLCJ3JpanNyCfXlHahZhYgJH9-rV6ouPro
If this seems interesting, please email us at [email protected] for a call.
Recent Comments
No comments
Leave a Comment
We will be happy to hear what you think about this post