An Introduction to BentoML: A Unified AI Application Framework
In this article, explore how to streamline the deployment of machine learning models using BentoML, a unified AI application framework.
Navigating the journey from building machine learning (ML) models to deploying them in production can often be a rocky road. It’s an essential yet complex process where data scientists and engineers must bridge their knowledge gap. Data scientists, adept at creating models, might stumble when it comes to production deployment. On the other hand, engineers may struggle with the continuous iteration of ML models, leading to inefficient, error-prone operations.
Consider this specific scenario: you have just created an ML model for text summarization, which performs brilliantly in tests. You plan to share this model with your team to build an application on top of it. However, shipping this model poses a unique challenge: ensuring your team can use your model without fiddling with code or environment setups.
Enter BentoML.
BentoML is an open-source ML model serving framework designed to streamline the deployment process. By facilitating a smoother handoff from model creation to production, this end-to-end framework allows data scientists and developers to focus on what they do best, bridging the gap between these two crucial roles. As a result, models can be deployed in a rapid and scalable manner, ensuring a more stable production service.
You can use the BentoML framework to develop a production-ready model serving endpoints. Here is the modus operandi of BentoML:
1. Specify a model: Before you use BentoML, you need to start with an ML model or a set of models. These models can be trained using various libraries such as TensorFlow or PyTorch.
2. Save the model: After you’ve trained your model, save it in the BentoML local Model Store. It serves as a management hub for all your models, providing easy access for serving as well as a systematic way to keep track of them.
3. Create a BentoML Service: You create
a service.py file to wrap your model and
lay out the serving logic. It specifies Runners (an abstraction in BentoML to
optimize inference) to execute model inference at scale and builds the
endpoints that you want to expose externally.
4. Build a Bento: This step involves packaging your model(s) and the BentoML Service into a Bento through a configuration YAML file. A Bento is a ready-to-deploy artifact that bundles together all necessary elements: your model’s code, its dependencies, and the serving logic. I will give you a more concrete example later.
5. Deploy the Bento: Once your Bento is prepared, it's time for deployment. You can containerize the Bento into a Docker image for deployment on Kubernetes. If you prefer an all-in-one solution, you can deploy your Bento directly to Yatai, an open-source platform in the BentoML ecosystem that automates and manages machine learning deployments on Kubernetes. If you want a fully-managed service, consider deploying Bentos through BentoCloud, a serverless solution for building and operating AI applications.
Now that you have a basic understanding of BentoML and its workflow let’s see an example of how BentoML simplifies model serving and deployment.
Setting up the Environment
To run this project locally, make sure you have the following:
- Python 3.8+
-
pipinstalled.
After that, create a directory to store all the project files,
including service.py as
mentioned above. I will create them one by one.
mkdir bentoml-democd bentoml-demo
I recommend you use a Virtual Environment for dependency isolation.
python -m venv venvsource venv/bin/activate
Create a requirements.txt file,
which contains all the required libraries.
bentomltransformerstorch>=2.0
Install the dependencies:
pip install -r requirements.txt
Downloading Models to the Local Model Store
In this blog post, I use a text summarization Transformer model (sshleifer/distilbart-cnn-12-6) from the Hugging Face Model Hub as an example.
As I mentioned above, you need to download the model to the
BentoML Model Store. This is done via a download_model.py script,
which uses the bentoml.transformers.save_model() function.
Create a download_model.py as
below.
import transformersimport bentoml model= "sshleifer/distilbart-cnn-12-6"task = "summarization" bentoml.transformers.save_model( task, transformers.pipeline(task, model=model), metadata=dict(model_name=model),)
Running this script should download and save your model locally.
python3 download_model.py
The model should appear in the Model Store if the download is successful. You can retrieve this model later to create a BentoML Service.
$ bentoml models list Tag Module Size Creation Time summarization:5kiyqyq62w6pqnry bentoml.transformers 1.14 GiB 2023-07-10 11:57:40
Note: All models
downloaded to the Model Store are saved in the directory /home/user/bentoml/models/.
Create a BentoML Service
With a ready-to-use model, you can create a BentoML Service by
defining a service.py file
as below. This script creates a summarizer_runner instance
from the previously downloaded model and wraps it within a bentoml.Service(). The summarize() function,
decorated with @svc.api(), specifies
the API endpoint for the Service and the logic to process the inputs and
outputs.
import bentoml summarizer_runner = bentoml.models.get("summarization:latest").to_runner() svc = bentoml.Service( name="summarization", runners=[summarizer_runner]) @svc.api(input=bentoml.io.Text(), output=bentoml.io.Text())async def summarize(text: str) -> str: generated = await summarizer_runner.async_run(text, max_length=3000) return generated[0]["summary_text"]
In the project directory, use bentoml
serve to start the BentoML server in development mode.
$ bentoml serve service:svc --development --reload 2023-07-10T12:13:33+0800 [INFO] [cli] Prometheus metrics for HTTP BentoServer from "service:svc" can be accessed at http://localhost:3000/metrics.2023-07-10T12:13:34+0800 [INFO] [cli] Starting production HTTP BentoServer from "service:svc" listening on http://0.0.0.0:3000 (Press CTRL+C to quit)2023-07-10 12:13:34 circus[5290] [INFO] Loading the plugin...2023-07-10 12:13:34 circus[5290] [INFO] Endpoint: 'tcp://127.0.0.1:61187'2023-07-10 12:13:34 circus[5290] [INFO] Pub/sub: 'tcp://127.0.0.1:61188'2023-07-10T12:13:34+0800 [INFO] [observer] Watching directories: ['/Users/sherlock/Documents/bentoml-demo', '/Users/sherlock/bentoml/models']
The server is now active at http://0.0.0.0:3000, which provides a web user interface that you can use. Visit the website, scroll down to Service APIs, and click Try it out.
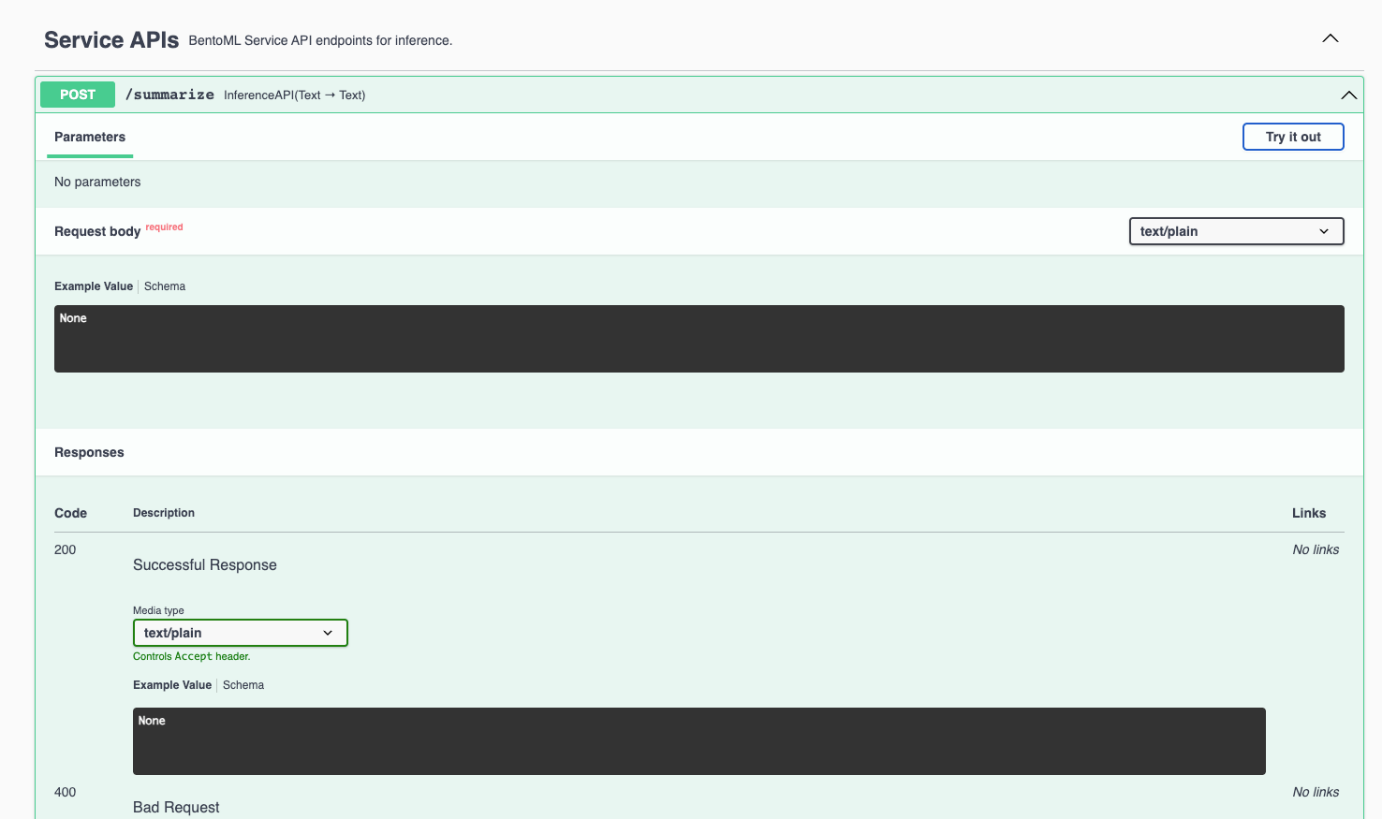
Enter your text in the Request body box and click Execute. See the following example about the concept of Large Language Models.
Input:
A large language model (LLM) is a computerized language model, embodied by an artificial neural network using an enormous amount of "parameters" (i.e. "neurons" in its layers with up to tens of millions to billions "weights" between them), that are (pre-)trained on many GPUs in relatively short time due to massive parallel processing of vast amounts of unlabeled texts containing up to trillions of tokens (i.e. parts of words) provided by corpora such as Wikipedia Corpus and Common Crawl, using self-supervised learning or semi-supervised learning, resulting in a tokenized vocabulary with a probability distribution. LLMs can be upgraded by using additional GPUs to (pre-)train the model with even more parameters on even vaster amounts of unlabeled texts.
Output by the text summarization model:
A large language model (LLM) is a computerized language model, embodied by an artificial neural network using an enormous amount of "parameters" in its layers with up to tens of millions to billions "weights" between them . LLMs can be upgraded by using additional GPUs to (pre-)train the model with even more parameters on even vaster amounts of unlabeled texts .
Building a Bento
Now that the model is functioning properly, you need to package
it into the standard distribution format in BentoML, also known as a “Bento.” A
Bento contains all the source code, model files, and dependencies required to
run the Service. To build a Bento, create a bentofile.yaml file
in the project directory. This file defines the build options, such as
dependencies, Docker image settings, and models. Here I just list the basic
information required to build a Bento, like the Service, Python files to be
included, and dependencies. See the BentoML
documentation to learn more.
service: 'service:svc'include: - '*.py'python: requirements_txt: requirements.txt
Run the bentoml build command
in the project directory to build the Bento. You can find all created Bentos
in /home/user/bentoml/bentos/.
$ bentoml build Building BentoML service "summarization:ulnyfbq66gagsnry" from build context "/Users/sherlock/Documents/bentoml-demo".Packing model "summarization:5kiyqyq62w6pqnry" ██████╗░███████╗███╗░░██╗████████╗░█████╗░███╗░░░███╗██╗░░░░░██╔══██╗██╔════╝████╗░██║╚══██╔══╝██╔══██╗████╗░████║██║░░░░░██████╦╝█████╗░░██╔██╗██║░░░██║░░░██║░░██║██╔████╔██║██║░░░░░██╔══██╗██╔══╝░░██║╚████║░░░██║░░░██║░░██║██║╚██╔╝██║██║░░░░░██████╦╝███████╗██║░╚███║░░░██║░░░╚█████╔╝██║░╚═╝░██║███████╗╚═════╝░╚══════╝╚═╝░░╚══╝░░░╚═╝░░░░╚════╝░╚═╝░░░░░╚═╝╚══════╝ Successfully built Bento(tag="summarization:ulnyfbq66gagsnry"). Possible next steps: * Containerize your Bento with `bentoml containerize`: $ bentoml containerize summarization:ulnyfbq66gagsnry * Push to BentoCloud with `bentoml push`: $ bentoml push summarization:ulnyfbq66gagsnry
To view all available Bentos, run the following:
$ bentoml list Tag Size Creation Timesummarization:ulnyfbq66gagsnry 1.25 GiB 2023-07-10 15:28:51
Deploy the Bento
Once the Bento is ready, you can use bentoml
serve to serve it in production. Note that if you have multiple
versions of the same model, you can change the latest tag to
the corresponding version.
$ bentoml serve summarization:latest 2023-07-10T15:36:58+0800 [INFO] [cli] Environ for worker 0: set CPU thread count to 122023-07-10T15:36:58+0800 [INFO] [cli] Prometheus metrics for HTTP BentoServer from "summarization:latest" can be accessed at http://localhost:3000/metrics.2023-07-10T15:36:59+0800 [INFO] [cli] Starting production HTTP BentoServer from "summarization:latest" listening on http://0.0.0.0:3000 (Press CTRL+C to quit)
Alternatively, you can containerize the Bento with Docker. When
creating the Bento, a Dockerfile was created automatically at /home/user/bentoml/bentos/summarization/ulnyfbq66gagsnry/env/docker/. To create
a Docker image, simply run the following:
bentoml containerize summarization:latest
View the created Docker image:
$ docker images REPOSITORY TAG IMAGE ID CREATED SIZEsummarization ulnyfbq66gagsnry da287141ef3e 7 seconds ago 2.43GB
You can run the Docker image locally:
docker run -it --rm -p 3000:3000 summarization:ulnyfbq66gagsnry serve
With the Docker image, you can run the model on Kubernetes and create a Kubernetes Service to expose it so that your users can interact with it.
If you are looking for an end-to-end solution for deploying models, you can choose Yatai to deploy Bentos and manage the deployment at scale on Kubernetes. Yatai is an important component in the BentoML ecosystem and deserves its own blog post to explain the details. If you are interested, take a look at the Yatai GitHub repository.
Conclusion
Getting your machine learning models from training to production is no small feat, and this is where BentoML really shines. With BentoML, you can focus on the model building while the framework takes care of the deployment intricacies.
As ML models become increasingly integral to business operations, having a streamlined model serving and deployment solution like BentoML will become indispensable. Not only does BentoML make deploying models a breeze, but it also ensures that your models are managed efficiently and can scale as per your needs. If you are interested, get started with BentoML today and experience the ease of model deployment. Happy coding!
We Provide consulting, implementation, and management services on DevOps, DevSecOps, DataOps, Cloud, Automated Ops, Microservices, Infrastructure, and Security
Services offered by us: https://www.zippyops.com/services
Our Products: https://www.zippyops.com/products
Our Solutions: https://www.zippyops.com/solutions
For Demo, videos check out YouTube Playlist: https://www.youtube.com/watch?v=4FYvPooN_Tg&list=PLCJ3JpanNyCfXlHahZhYgJH9-rV6ouPro
If this seems interesting, please email us at [email protected] for a call.
Relevant Blogs:
Review AWS ECS vs. Kubernetes: The Complete Guide
Recent Comments
No comments
Leave a Comment
We will be happy to hear what you think about this post